Stay Confident
Subscribe to our weekly newsletter to stay confident in the AI systems you build.

AI Agent Observability: Everything You Need to Know in 2026
Everything you need to know about AI agent observability in 2026 — traces, spans, and threads; online and offline evals; production monitoring; and closing the feedback loop so failures never repeat.

Kritin Vongthongsri

Human-in-the-Loop Workflows for AI Agent Evaluation: Complete Guide
A practical guide to human-in-the-loop workflows for AI agent evaluation: how SMEs review AI agent failures, align automated metrics, and improve evaluation datasets.
Kritin Vongthongsri

LLM Product Manager Workflows: A Complete Guide to AI Quality
A practical guide to LLM product manager workflows, built around the two things PMs can finally do without waiting on engineering: build on the AI product by editing prompts, running evals, and comparing variants, and monitor quality with dashboards, signals, and shareable evidence.
Kritin Vongthongsri

The Complete Guide to LLM Experimentation: Compare Prompts, Models, and Agents
A practical guide to running LLM experiments across prompts, models, tools, datasets, metrics, production A/B tests, and human-in-the-loop feedback loops.
Kritin Vongthongsri

LLM Evaluation for Startups: The Complete Guide
A practical LLM evaluation guide for startups: build a small dataset, use the 2 + 3 metric rule, run CI/CD evals, and grow coverage from production signals and human review.
Kritin Vongthongsri
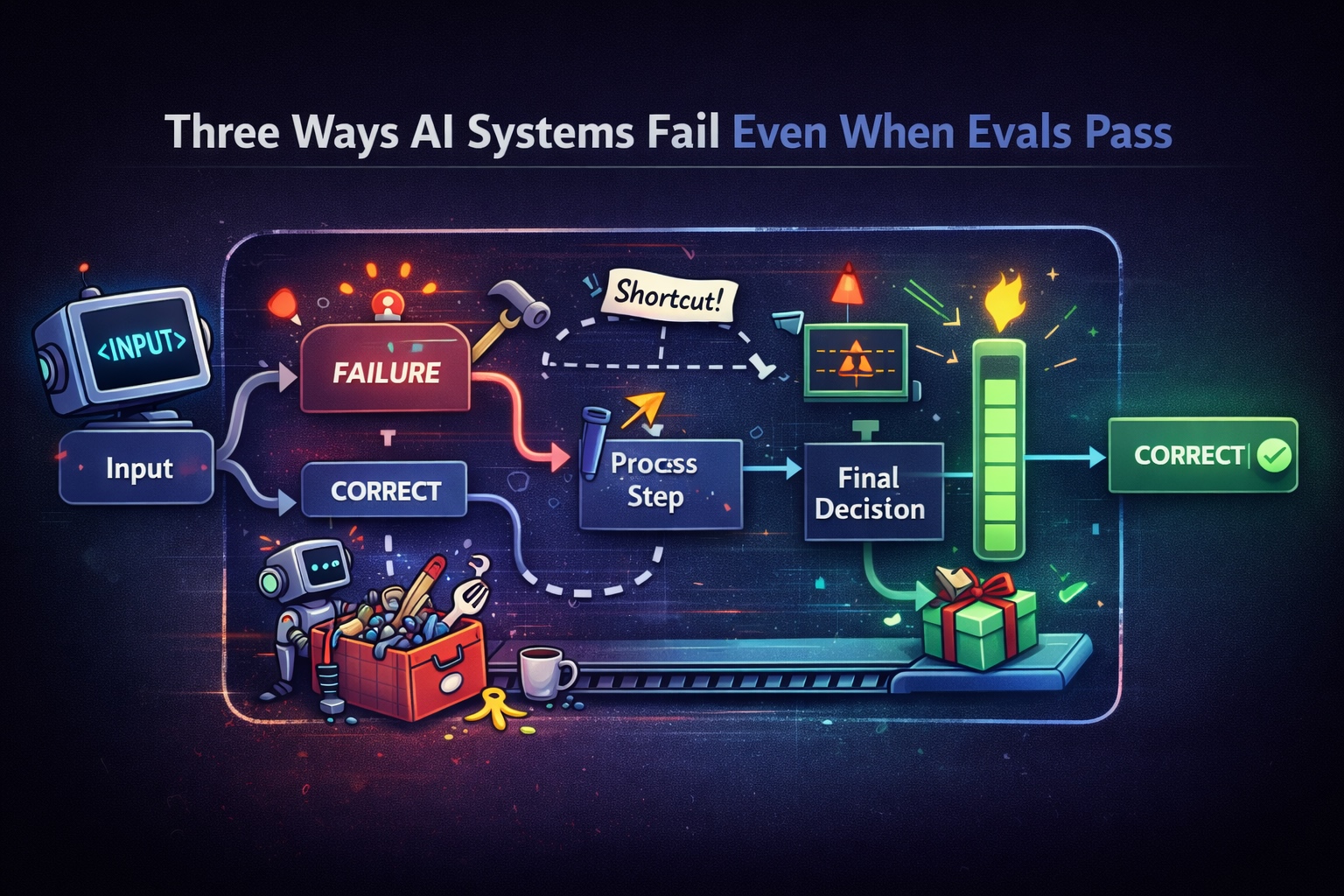
Three Ways AI Systems Fail Even When Evals Pass
AI systems can pass evals while still behaving incorrectly. This post explores three common failure modes that slip through output-based evaluation.

Brian Neville-O'Neill
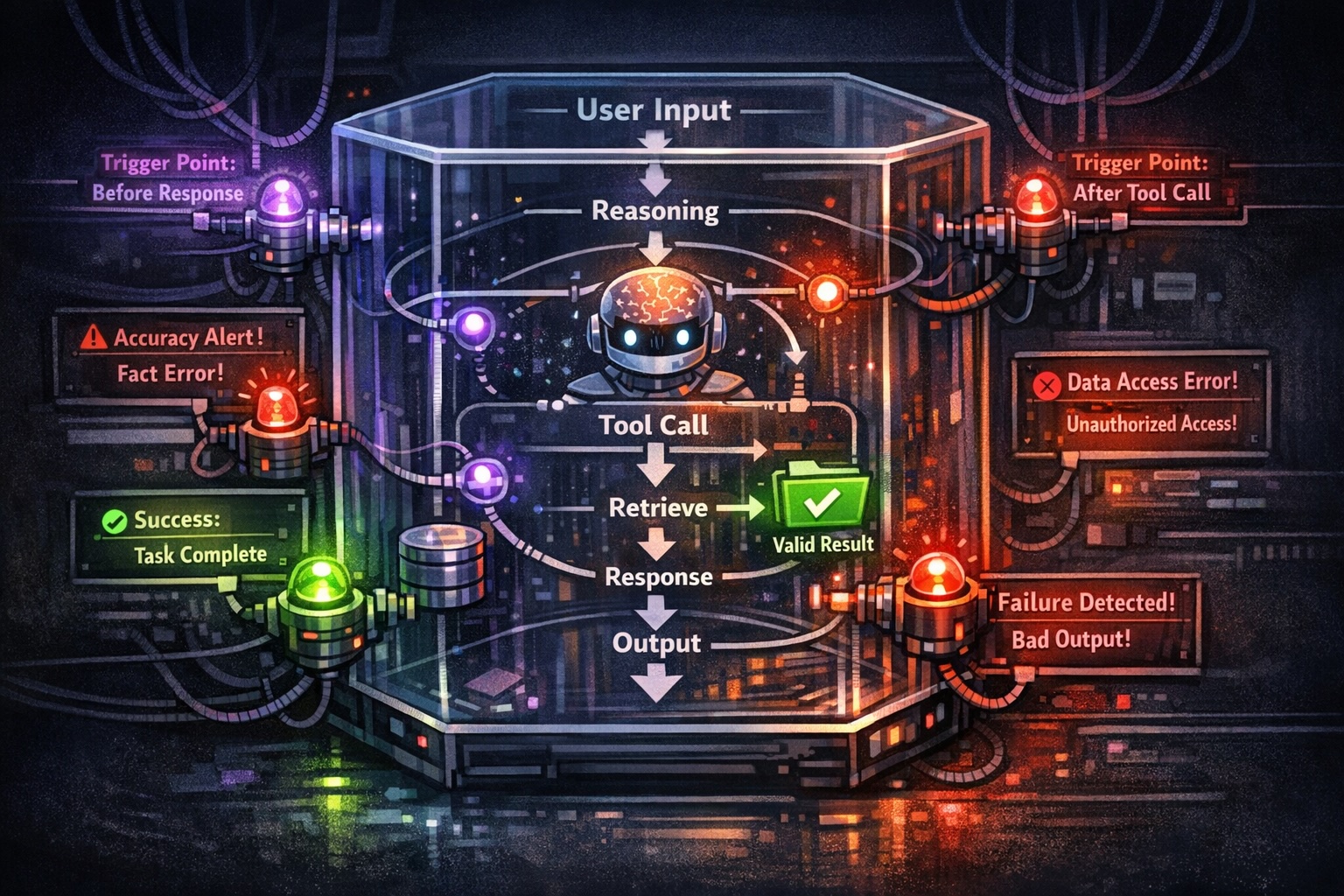
Your AI Agent Passed Evals. That’s the Problem.
Passing evals doesn't mean your AI agent works — it means your tests missed how it fails. Why output-based evals create false confidence and what to measure instead.
Brian Neville-O'Neill

Multi-Turn LLM Evaluation in 2026: What You Need to Know
In this article, I'll break down multi-turn LLM evaluation — how it differs from single-turn, what metrics actually matter, and how to implement it.

Jeffrey Ip

The Step-By-Step Guide to MCP Evaluation
A step-by-step guide to MCP evaluation: how to test MCP-based LLM apps and agents, measure tool use and task completion, and catch failures with DeepEval.

Cale

AI Agent Evaluation: Metrics, Traces, Human Review, and Workflows
A practical guide to evaluating AI agents with LLM metrics and tracing—plus when human review matters, how it calibrates judges, and workflows that combine CI, sampling, and production signals.