

Building a Retrieval-Augmented Generation (RAG) pipeline isn’t the mission impossible — knowing if it’s actually working is. You might fine-tune prompts, tweak retrievers, and switch models, but if your system is still hallucinating or citing the wrong context, what’s really broken? Without the right RAG evaluation metrics, it’s guesswork.
Sure, 2025 is the year of AI agents, but let’s face it: most agentic system still has a RAG pipeline somewhere in their AI workflow, and it’s vital that you’re about to secure the quality of that too.
So, in this article, we’ll go through everything you’ll need for RAG evaluation:
- What is RAG evaluation, how is it different from regular LLM and AI agent evaluation, and common points of failure
- Retriever metrics such as contextual relevancy, recall, and precision
- Generator metrics such as answer relevancy and faithfulness
- How to run RAG evaluation: both end-to-end and at a component-level
- Best practices, including RAG evaluation in CI pipelines and post-deployment monitoring
All of course, this all includes code samples using DeepEval ⭐, an open-source LLM evaluation framework. Let’s get started.
TL;DR
- RAG pipelines are made up of a retriever and a generator, both of which contribute to the quality of the final response.
- RAG metrics measures either the retriever and generator in isolation, focusing on relevancy, hallucination, and retrieval.
- Retriever metrics include: Contextual recall, precision, and relevancy, used for evaluating things like top-K values and embedding models.
- Generator metrics include: Faithfulness and answer relevancy, used for evaluating the LLM and prompt template.
- RAG metrics are generic, and you'll want to use at least one additional custom metric to tailor towards your use case.
- Agentic RAG requires additional metrics such as task completion.
- DeepEval (100% OS ⭐ https://github.com/confident-ai/deepeval) allows anyone to implement SOTA RAG metrics in 5 lines of code.
What is RAG Evaluation?
RAG evaluation is the process of using metrics such as answer relevancy, faithfulness, and contextual relevancy to test the quality of a RAG pipeline’s “retriever” and the “generator” separately to measure each component’s contribution to the final response quality
To do this, RAG evaluation involves 5 key industry-standard metrics:
- Answer Relevancy: How relevant the generated response is to the given input.
- Faithfulness: Whether the generated response contains hallucinations to the retrieval context.
- Contextual Relevancy: How relevant the retrieval context is to the input.
- Contextual Recall: Whether the retrieval context contains all the information required to produce the ideal output (for a given input).
- Contextual Precision: Whether the retrieval context is ranked in the correct order (higher relevancy goes first) for a given input.
For agentic RAG use cases, which we'll cover more in a later section, you might also find it useful to include a task completion metric to evaluate your AI agent RAG pipeline as well.
Before we get too into the metrics though and RAG agents, let’s recap what RAG is. A RAG pipeline is an architecture where an LLM’s output is informed by external data that is retrieved at runtime based on an input. Rather than relying solely on the model’s trained knowledge, a RAG system first:
- Searches a knowledge source — like a document database, vector store, or API, then
- Feeds the retrieved content into the prompt for the LLM to generate a response.
Here’s a diagram showing how RAG works:

A RAG Pipeline Architecture
You’ll notice that the quality of the final generation is highly dependent on the retriever doing its job well. A RAG pipeline can only produce a helpful, factually correct response if it:
- Has access to the right context.
- Does not hallucinate, and follows instructions given the right context.
In fact, the quality of your RAG generation is only as strong as its weakest component — retriever or generator. Think of it as a product, not a sum: if either the retriever or the generator performs poorly (or fails entirely), the overall quality of the output can drop to zero, regardless of how well the other performs.
So the question becomes: how do we evaluate both the retriever and the generator independently to understand where the failures are happening in a RAG pipeline?
Ways In Which Your RAG Pipeline Can Fail
You can address this by using retriever-targeted and generator-targeted metrics that evaluate each component separately, focusing on the most common failure modes within each stage of the pipeline.
When the retriever fails, it often due to the following:
- Uninformative embeddings (by your embedding model)
- Poor chunking strategy (caused by chunk size, partitioning logic, etc.)
- Weak reranking logic
- Suboptimal Top-K setting
This forces the LLM to “fill in the blanks,” leading to hallucinations or confidently wrong answers. Even with good retrieval, the generator can still fail to use the context effectively:
- Ignores key information
- Focuses on the wrong details
- Misreads the prompt structure
- Suffers from weak prompts or model limitations
Now with this in mind, it’s time to talk about how retrieval and generation metrics tackle each one of them.
Important Note: If your “RAG” pipeline involves “hard-coded” retrieval, where retrieval literally cannot go wrong (for example, fetching user data based on user ID and supplying that information into your prompt), there is no need for RAG evaluation per se, you can just do regular LLM system evaluation or even better, do agent evaluation instead if the process of fetching data is a tool calling one
Standardize AI Quality for the entire org, not just individual teams
Give all AI use cases the same quality bar with all-in-one evals, observability, and red teaming, and enforce them at scale.
Retrieval Evaluation Metrics
The retrieval step typically consists of three main stages:
- Embedding the query: Convert the input into a vector representation using an embedding model of your choice (e.g., OpenAI’s
text-embedding-3-large). - Vector search: Use this embedded query to search a vector store containing your pre-embedded knowledge base, retrieving the top-K most similar text chunks.
- Reranking: Refine the initial results by reranking the retrieved chunks, since raw vector similarity may not always reflect true relevance for your specific use case.

Retriever in RAG
Which involves several tunable hyperparameters — like the embedding model, chunk size, and top-K. Retrieval metrics help answer key questions such as:
- Is your embedding model domain-aware?
A generic model might miss nuances in specialized fields like medicine.
- Is your reranker ordering results correctly?
Initial vector search may not reflect true relevance.
- Are you retrieving the right amount of context?
Chunk size and Top-K directly affect how much and what gets passed to the generator.
Retrieval metrics uses a variation of QAG (question-answer-generation) to compute metric scores, which is a great technique used by LLM evaluators to combat arbitary score calculations.
Contextual Relevancy
The contextual relevancy metric uses LLM-as-a-judge to quantify the proportion of retrieved text chunks that are relevant to the input. It is a measure of how well your top-K and chunk size is configured. Smaller chunks can give you more precise information, but they often require retrieving more of them (higher top-K) to cover enough context, while larger chunks may capture broader meaning but risk including irrelevant details.
You can definitely build something to loop through all your text chunks, handle asynchronously LLM-as-a-judge evals for judging relevancy, and compute the final score, however if you want something that just works out of the box, I’d recommend DeepEval ⭐, the open-source LLM evaluation framework with all the RAG metrics you can imagine:
from deepeval.test_case import LLMTestCase
from deepeval.metrics import ContextualRelevancyMetric
# Replace this with the actual output from your LLM application
actual_output = "We offer a 30-day full refund at no extra cost."
# Replace this with the actual retrieved context from your RAG pipeline
retrieval_context = ["All customers are eligible for a 30 day full refund at no extra cost."]
metric = ContextualRelevancyMetric(threshold=0.7, model="gpt-4")
test_case = LLMTestCase(
input="What if these shoes don't fit?",
actual_output=actual_output,
retrieval_context=retrieval_context
)
metric.measure(test_case)
print(metric.score, metric.reason)Note that you should click here to learn what a test case is.
The threshold parameter in the ContextualRelevancyMetric tells DeepEval what is the acceptable proportion of relevant text chunks for a test case to pass, while the model determines which model should be used to determine each text chunk’s relevancy.
For more information, find DeepEval’s full documentation here.
Contextual Recall
The contextual recall metric is a reference-baed metric that uses LLM-as-a-judge to quantify the proportion undisputed facts found in the labelled, expected output for a given input can be attributed to the retrieved text chunks. It measures the embedding model parameter.
The whole purpose of contextual recall is to assess whether the retrieval context actually contains all the necessary information to produce the ideal output. Without contextual recall, anyone can achieve perfect contextual relevancy by retrieving as little information as possible.
Here’s the code implementation in DeepEval (docs here):
from deepeval.test_case import LLMTestCase
from deepeval.metrics import ContextualRecallMetric
# Replace this with the actual output from your LLM application
actual_output = "We offer a 30-day full refund at no extra cost."
# Replace this with the expected output from your RAG generator
expected_output = "You are eligible for a 30 day full refund at no extra cost."
# Replace this with the actual retrieved context from your RAG pipeline
retrieval_context = ["All customers are eligible for a 30 day full refund at no extra cost."]
metric = ContextualRecallMetric(threshold=0.7, model="gpt-4")
test_case = LLMTestCase(
input="What if these shoes don't fit?",
actual_output=actual_output,
expected_output=expected_output,
retrieval_context=retrieval_context
)
metric.measure(test_case)
print(metric.score, metric.reason)Contextual Precision
The contextual precision metric is a reference-baed metric that uses LLM-as-a-judge to quantify whether relevant text chunks are ranked higher than irrelevant ones. It measures the quality of your reranker, and follows a rather complicated equation that you can learn more about here.
The purpose of precision is to make sure that the context you are feeding into your generator is not just relevant, contains all the information, but also in the correct order for an LLM to consider each text chunk’s importance appropriately.
Here’s how you can use it in DeepEval:
from deepeval.test_case import LLMTestCase
from deepeval.metrics import ContextualPrecisionMetric
# Replace this with the actual output from your LLM application
actual_output = "We offer a 30-day full refund at no extra cost."
# Replace this with the expected output of your RAG generator
expected_output = "You are eligible for a 30 day full refund at no extra cost."
# Replace this with the actual retrieved context from your RAG pipeline
retrieval_context = ["All customers are eligible for a 30 day full refund at no extra cost."]
metric = ContextualPrecisionMetric(threshold=0.7, model="gpt-4")
test_case = LLMTestCase(
input="What if these shoes don't fit?",
actual_output=actual_output,
expected_output=expected_output,
retrieval_context=retrieval_context
)
metri.measure(test_case)
print(metric.score, metric.reason)Full documentation here.
(Note that you should aim to use all three contextual metrics in order to evaluate your retriever fully.)
Standardize AI Quality for the entire org, not just individual teams
Give all AI use cases the same quality bar with all-in-one evals, observability, and red teaming, and enforce them at scale.
Generation Evaluation Metrics
The generation step, which follows retrieval, typically involves two key stages:
- Prompt construction: Combine the user’s original input with the retrieved context to form a complete prompt.
- LLM generation: Send this prompt to your language model (e.g., GPT-4, Claude, or an open-source model) to generate the final output.
An example generator can be as simple as this:
prompt = """You are a helpful assistant. Use the information provided in the context below to answer the user's question. If the answer is not found in the context, say "I don't know based on the provided information."
Context:
{retrieval_context}
Question:
{user_query}
Answer:"""
res = openai.ChatCompletion.create(
model="gpt-4",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": prompt}
],
temperature=0.2
)
print(res.choices[0].message["content"])Compared to retrieval, generation is usually more straightforward — thanks to standardized APIs and model interfaces — but generation metrics still help answer key questions like:
- Is your model hallucinating given the retrieval context?
- Can you switch to a smaller, cheaper model?
- Does temperature tuning improve results?
- How sensitive is output to prompt template changes?
You’ll also likely need custom, task specific metrics to evaluate RAG generation, as we’ll go through why and how later. Similar to retrieval metrics, generation metrics also leverages LLM evaluators with QAG.
Answer Relevancy
The answer relevancy metric quantifies the proportion of the generated output that is relevant to the given input. It is extremely straightforward and a direct measure of how well your model is able to follow instructions in your prompt template.
Here’s how you can use answer relevancy in DeepEval:
from deepeval.metrics import AnswerRelevancyMetric
from deepeval.test_case import LLMTestCase
metric = AnswerRelevancyMetric(threshold=0.7, model="gpt-4")
test_case = LLMTestCase(
input="What if these shoes don't fit?",
# Replace this with the output from your LLM app
actual_output="We offer a 30-day full refund at no extra cost."
)
metric.measure(test_case)
print(metric.score, metric.reason)Full documentation here.
Faithfulness
The faithfulness metric quantifies the proportion of undisputed, truthful facts in the retrieval context that were not contradicted in the generated output. In other words, it measures the hallucination rate of your LLM.
Here’s how to use it in DeepEval:
from deepeval.test_case import LLMTestCase
from deepeval.metrics import FaithfulnessMetric
# Replace this with the actual output from your LLM application
actual_output = "We offer a 30-day full refund at no extra cost."
# Replace this with the actual retrieved context from your RAG pipeline
retrieval_context = ["All customers are eligible for a 30 day full refund at no extra cost."]
metric = FaithfulnessMetric(
threshold=0.7,
model="gpt-4",
include_reason=True
)
test_case = LLMTestCase(
input="What if these shoes don't fit?",
actual_output=actual_output,
retrieval_context=retrieval_context
)
metric.measure(test_case)
print(metric.score, metric.reason)Full documentation here.
Custom G-Eval
Often times your RAG pipeline is not a generic QA, and has some aspects of customizations. It might be that responses has to be generated in a certain format (e.g. bullet points, markdown, JSON, etc.), which the generic RAG metrics can’t account for.
For this reason, you’ll want custom metrics that evaluates based on your unique use case. Also note that a custom RAG metric belongs to the generation category of metrics because a retriever is not where task-specific customizations are done.
There are various ways you can built a custom metric, but here we are going to use one of DeepEval’s most versatile metric, G-Eval. G-Eval (full read here) is almost capable of evaluating any task and you can define its criteria in everyday language.
from deepeval.metrics import GEval
from deepeval.test_case import LLMTestCase, LLMTestCaseParams
metric = GEval(
name="Format",
criteria="Determine whether the actual output is in Spanish.",
evaluation_params=[LLMTestCaseParams.ACTUAL_OUTPUT],
strict_mode=True
)
test_case = LLMTestCase(
input="What if these shoes don't fit?",
actual_output="Ofrecemos un reembolso completo de 30 días sin costo adicional."
)
metric.measure(test_case)
print(metric.score, metric.reason)In this example, we set our criteria as whether our generator is able to generate outputs in spanish consistently. You’ll notice that we set the strict_mode parameter on G-Eval as True . This tells DeepEval that G-Eval should only output a binary score (0 or 1) instead of a continuous one. which makes a lot of sense for this use case.
You can find the documentation for G-Eval here and the most used G-Eval use cases in DeepEval here.
Standardize AI Quality for the entire org, not just individual teams
Give all AI use cases the same quality bar with all-in-one evals, observability, and red teaming, and enforce them at scale.
Agentic RAG Evaluation Metrics
When working with RAG in AI agents, the retrieval and generation metrics from above still apply. However, you'll want to also include end-to-end metrics to assess the overall success of your RAG AI agent. We already went through more of evaluating AI agents in this article in-depth, but here is a quick diagram of a what an AI agent is:
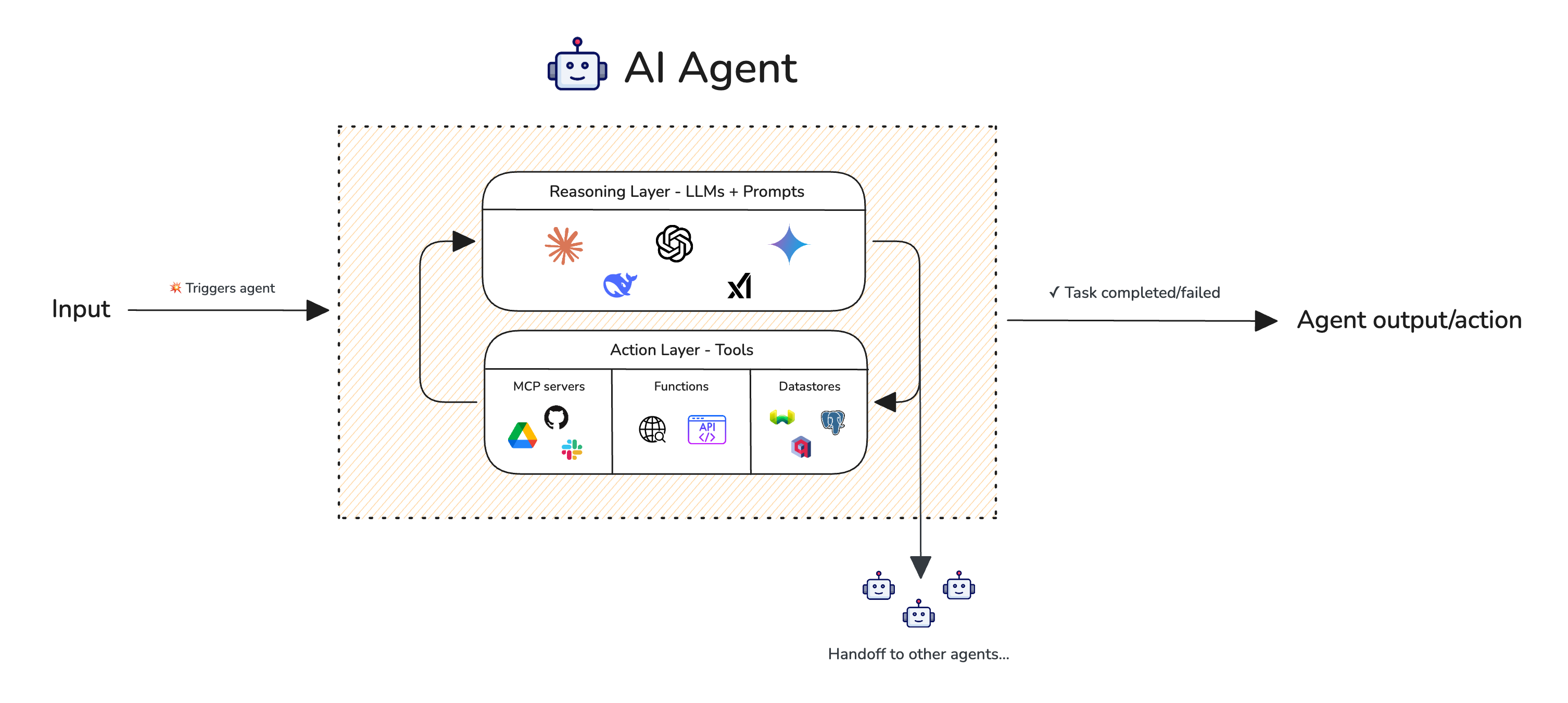
Single-turn AI agent with tools and ability to handoff to other agents
As you can see, an AI agent is an AI system with an LLM which has the ability to reason and determine whether certain tools has to be involved in order to complete a task. In the context of agentic RAG, this means tools that can have access to knowledge bases, which includes things like Qdrant's MCP server if you data is kept in this vector database, or an API to hit ChomaDB's servers directly to fetch data you have indexed.
When considering agentic RAG, a common reason things fail is because it is not able to call the correct tools with the correct arguments. This leads to a failure in completing the task at hand, leading to a decrease in your agentic RAG's overall success rate.
You should 100% click on this article to learn more about the task completion and argument correctness metric, but in summary the two main metrics you ought to consider are:
- Task completion: A single-turn, end-to-end LLM-as-a-judge metric that measures an AI agent’s degree of task completion based on an LLM trace
- Argument correctness: A component-level LLM-as-a-judge metric that assesses an LLM’s ability to generate the correct input argument parameters for a certain tool call
RAG Evaluation Workflows Best Practices
There are a few evaluation workflows you can adopt, mainly around automating the testing of your RAG pipeline in different ways (end-to-end vs component-level) and environments (in a script vs in CI/CD).
End-to-end
End-to-end evaluation refers to the process of treating your RAG pipeline as a blackbox and only caring about the “observable” inputs, outputs, and retrieval context of your LLM system. Most RAG evaluation modeled as end-to-end systems, while LLM agent evaluation is more appropriate on the component-level (more on this later).
This is straightforward using tools like DeepEval, simply have a dataset of inputs to loop through, and generate responses for each input. Finally, apply the 5 metrics you’ve learnt from above (as well as any custom ones), and that’s all:
from deepeval.metrics import (
AnswerRelevancyMetric,
FaithfulnessMetric,
ContextualRelevancyMetric,
ContextualRecallMetric,
ContextualPrecisionMetric
)
from deepeval import evaluate
test_cases = []
inputs = ["...", "...", "...", "..."]
for input in inputs:
# Replace your_llm_app()
actual_output, retrieval_context = your_llm_app(input)
test_case = LLMTestCase(
input=input,
actual_output=res,
retrieval_context=retrieval_context
)
test_cases.append(test_case)
evaluate(
test_cases=test_cases,
metrics=[
AnswerRelevancyMetric(),
FaithfulnessMetric(),
ContextualRelevancyMetric(),
ContextualRecallMetric(),
ContextualPrecisionMetric(),
]
)The full documentation for end-to-end evaluation available here, which you’ll also get a nice testing report if used alongside DeepEval’s cloud platform Confident AI.
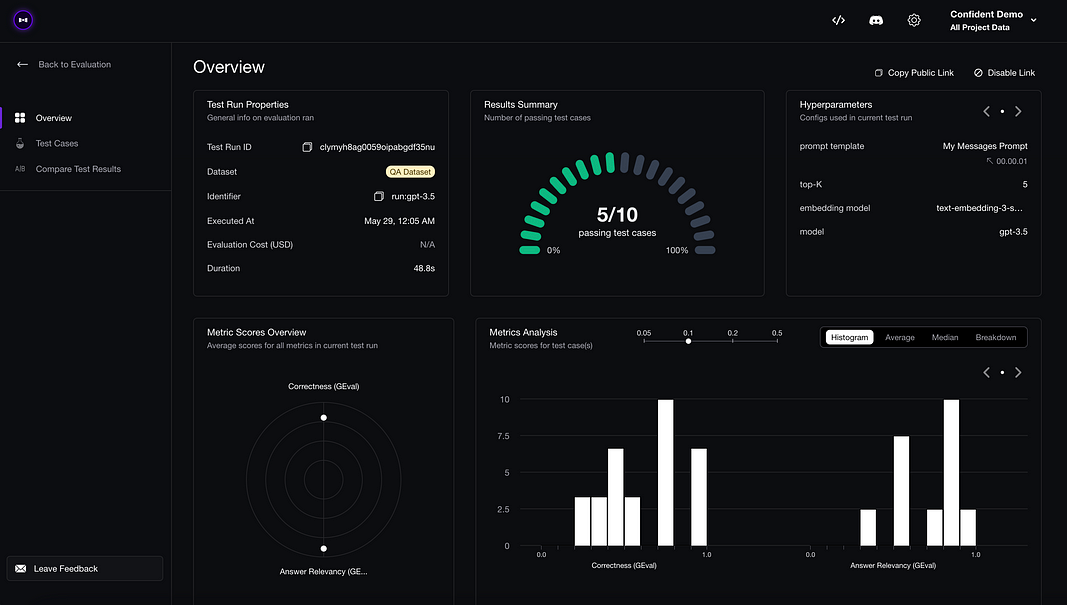 Testing reports on Confident AI.
Testing reports on Confident AI.Component-Level
Component-level evaluation works similar to end-to-end in the context of RAG evaluation, but only now we treat your retriever and generator as a nested component within your RAG pipeline instead.
This avoids messy rewrites of your codebase, returning variables in awkward places just to run evals (as seen in the previous example where we had to return both the response and retrieval context from your_llm_app)
You’ll also create test cases at runtime instead of outside the context of an evaluation. Here’s a quick example:
from typing import List
import openai
from deepeval.tracing import observe, update_current_span
from deepeval.test_case import LLMTestCase
from deepeval.metrics import AnswerRelevancyMetric
def your_llm_app(input: str):
def retriever(input: str):
return ["Hardcoded text chunks from your vector database"]
@observe(metrics=[AnswerRelevancyMetric()])
def generator(input: str, retrieved_chunks: List[str]):
res = openai.ChatCompletion.create(
model="gpt-4o",
messages=[
{"role": "system", "content": "Use the provided context to answer the question."},
{"role": "user", "content": "\n\n".join(retrieved_chunks) + "\n\nQuestion: " + input}
]
).choices[0].message["content"]
# Create test case at runtime
update_current_span(test_case=LLMTestCase(input=input, actual_output=res))
return res
return generator(input, retriever(input))
evaluate(goldens=goldens, observed_callback=your_llm_app)For simplicity purposes, we did not:
- Use all the metrics, just answer relevancy
- Explain what a golden is, as you can learn more here
However notice how we have an @observe decorator on top of the generator function? DeepEval is great because it allows you to run targetted evals to any individual component instead.
The full documentation for component-level evals is available here, which again when used alongside Confident AI gives you an entire debugging UI:
 RAG component-level evals on Confident AI.
RAG component-level evals on Confident AI.In CI/CD Pipelines
As introduced in one of my earlier articles on LLM testing, you can incorporate BOTH end-to-end and component-level evals in CI/CD. Here, we’ll show end-to-end RAG evaluation, but you’ll equally find how to do component-level evals in CI/CD in the links I showed above.
First create a test file:
import pytest
from deepeval.metrics import (
AnswerRelevancyMetric,
FaithfulnessMetric,
ContextualRelevancyMetric,
ContextualRecallMetric,
ContextualPrecisionMetric
)
from deepeval import assert_test
inputs = ["...", "...", "...", "..."]
# Loop through goldens using pytest
@pytest.mark.parametrize("input", inputs)
def test_llm_app(input: str):
res, text_chunks = your_llm_app(str)
test_case = LLMTestCase(input=golden.input, actual_output=res, retrieval_context=text_chunks)
assert_test(test_case=test_case, metrics=[...])Then run it using DeepEval’s native Pytest integration:
deepeval test run test_filename.pyAnd that’s it! Full documentation here.
Conclusion
In this article, we talked about how a RAG pipeline is only as good as it’s worst performing component, hence why we separate the evaluation of the retriever and generator.
Retriever has targeted LLM-as-a-judge metrics such as contextual relevancy, recall, and precision, while the generator has answer relevancy, faithfulness, and G-Eval to evaluate it’s performance. We also learnt that these metrics can be applied to evaluate RAG pipelines from an end-to-end perspective, or at a component-level. Both of these modes of evaluation can then be ran using a raw Python script, or in CI/CD pipelines.
Beyond the theory, all of this can be implemented in a few lines of code code using DeepEval, as it takes care of a lot of boring repetitive tasks such as running tests async in CI/CD, handling exceptions during evaluation, implementation of metrics, etc.
Don’t forget to give ⭐ DeepEval a star on Github ⭐ if you found this article useful, and as always, till next time.
Do you want to brainstorm how to evaluate your LLM (application)? Ask us anything in our discord. I might give you an "aha!" moment, who knows?
Standardize AI Quality for the entire org, not just individual teams
Give all AI use cases the same quality bar with all-in-one evals, observability, and red teaming, and enforce them at scale.