

It is no secret that evaluating the outputs of Large Language Models (LLMs) is essential for anyone building robust LLM applications. Whether you're fine-tuning for accuracy, enhancing contextual relevance in a RAG pipeline, or increasing task completion rate in an AI agent, choosing the right evaluation metrics is critical. Yet, LLM evaluation remains notoriously difficult—especially when it comes to deciding what to measure and how.
Having built one of the most adopted LLM evaluation framework myself, this article will teach you everything you need to know about LLM evaluation metrics, with code samples included. Ready for the long list? Let’s begin.
(Update: For metrics evaluating AI agents, heck out this new article)
TL;DR
Key takeaways:
- LLM metrics measures output quality across dimensions like correctness and relevance.
- Common mistakes: relying on traditional scorers like BLEU/ROUGE, where semantic nuance in LLM outputs is not captured.
- LLM-as-a-judge is the most reliable method—using an LLM to evaluate with natural language rubrics, but requires various techniques like G-Eval.
- Evaluation metrics in the context of LLM evaluation can be categorized as either single or multi-turn, targeting end-to-end LLM systems or at a component-level.
- Metrics for AI agents, RAG, chatbots, and foundational models are all different and has to be complimented with use case specific ones (e.g. Text-SQL, writing assistants).
- DeepEval (100% OS ⭐https://github.com/confident-ai/deepeval) allows anyone to implement SOTA LLM metrics in 5 lines of code.
What are LLM Evaluation Metrics?
LLM evaluation metrics such as answer correctness, semantic similarity, and hallucination, are metrics that score an LLM system's output based on criteria you care about. They are critical to LLM evaluation, as they help quantify the performance of different LLM systems, which can just be the LLM itself.
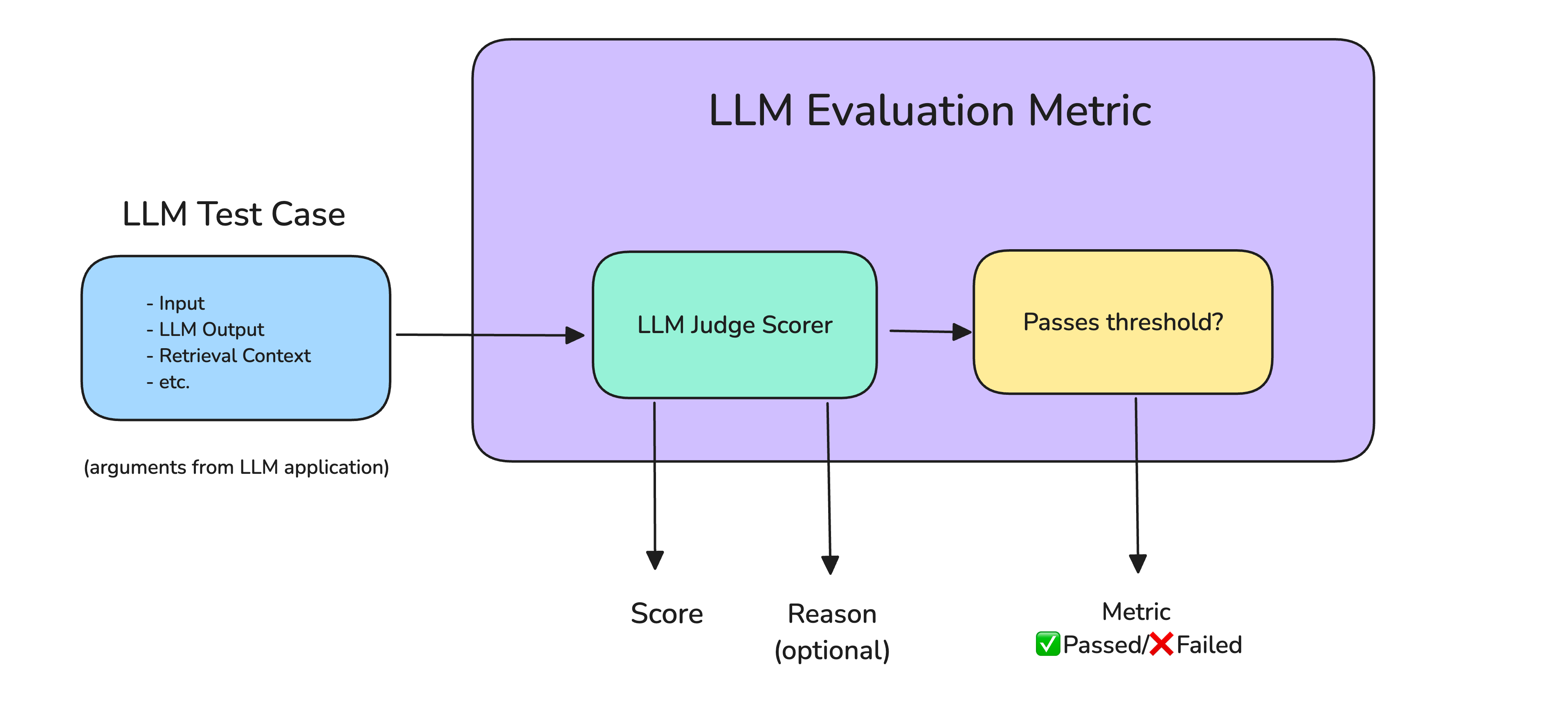
An LLM Evaluation Metric Architecture
Here are the most important and common metrics that you will likely need before launching your LLM system into production:
- Answer Relevancy: Determines whether an LLM output is able to address the given input in an informative and concise manner.
- Task Completion: Determines whether an LLM agent is able to complete the task it was set out to do.
- Correctness: Determines whether an LLM output is factually correct based on some ground truth.
- Hallucination: Determines whether an LLM output contains fake or made-up information.
- Tool Correctness: Determines whether an LLM agent is able to call the correct tools for a given task.
- Contextual Relevancy: Determines whether the retriever in a RAG-based LLM system is able to extract the most relevant information for your LLM as context.
- Responsible Metrics: Includes metrics such as bias and toxicity, which determines whether an LLM output contains (generally) harmful and offensive content.
- Task-Specific Metrics: Includes metrics such as summarization, which usually contains a custom criteria depending on the use-case.
While most metrics are generic and necessarily, they are not sufficient to target specific use-cases. This is why you'll want at least one custom task-specific metric to make your LLM evaluation pipeline production ready (as you'll see later in the G-Eval and DAG sections). For example, if your LLM application is designed to summarize pages of news articles, you’ll need a custom LLM evaluation metric that scores based on:
- Whether the summary contains enough information from the original text.
- Whether the summary contains any contradictions or hallucinations from the original text.
Moreover, if your LLM application has a RAG-based architecture, you’ll probably need to score for the quality of the retrieval context as well. The point is, an LLM evaluation metric assesses an LLM application based on the tasks it was designed to do. (Note that an LLM application can simply be the LLM itself!)
In fact, this is why LLM-as-a-Judge is the preferred way to compute LLM evaluation metrics, which we will talk more in-depth later:

Single-Turn LLM-as-a-Judge
What makes great metrics?
That brings us to one of the most important points - your choice of LLM evaluation metrics should cover both the evaluation criteria of the LLM use case and the LLM system architecture:
- LLM Use Case: Custom metrics specific to the task, consistent across different implementations.
- LLM System Architecture: Generic metrics (e.g., faithfulness for RAG, task completion for agents) that depend on how the system is built.
If you decide to change your LLM system completely tomorrow for the same LLM use case, your custom metrics shouldn't change at all, and vice versa. We'll talk more about the best strategy to choose your metrics later (spoiler: you don't want to have more than 5 metrics), but before that let's go through what makes great metrics great.
Great evaluation metrics are:
- Quantitative. Metrics should always compute a score when evaluating the task at hand. This approach enables you to set a minimum passing threshold to determine if your LLM application is “good enough” and allows you to monitor how these scores change over time as you iterate and improve your implementation.
- Reliable. As unpredictable as LLM outputs can be, the last thing you want is for an LLM evaluation metric to be equally flaky. So, although metrics evaluated using LLMs (aka. LLM-as-a-judge or LLM-Evals), such as G-Eval and especially for DAG, are more accurate than traditional scoring methods, they are often inconsistent, which is where most LLM-Evals fall short.
- Accurate. Reliable scores are meaningless if they don’t truly represent the performance of your LLM application. In fact, the secret to making a good LLM evaluation metric great is to make it align with human expectations as much as possible.
So the question becomes, how can LLM evaluation metrics compute reliable and accurate scores?
Different Ways to Compute Metric Scores
In one of my previous articles, I talked about how LLM outputs are notoriously difficult to evaluate. Fortunately, there are numerous established methods available for calculating metric scores — some utilize neural networks, including embedding models and LLMs, while others are based entirely on statistical analysis.
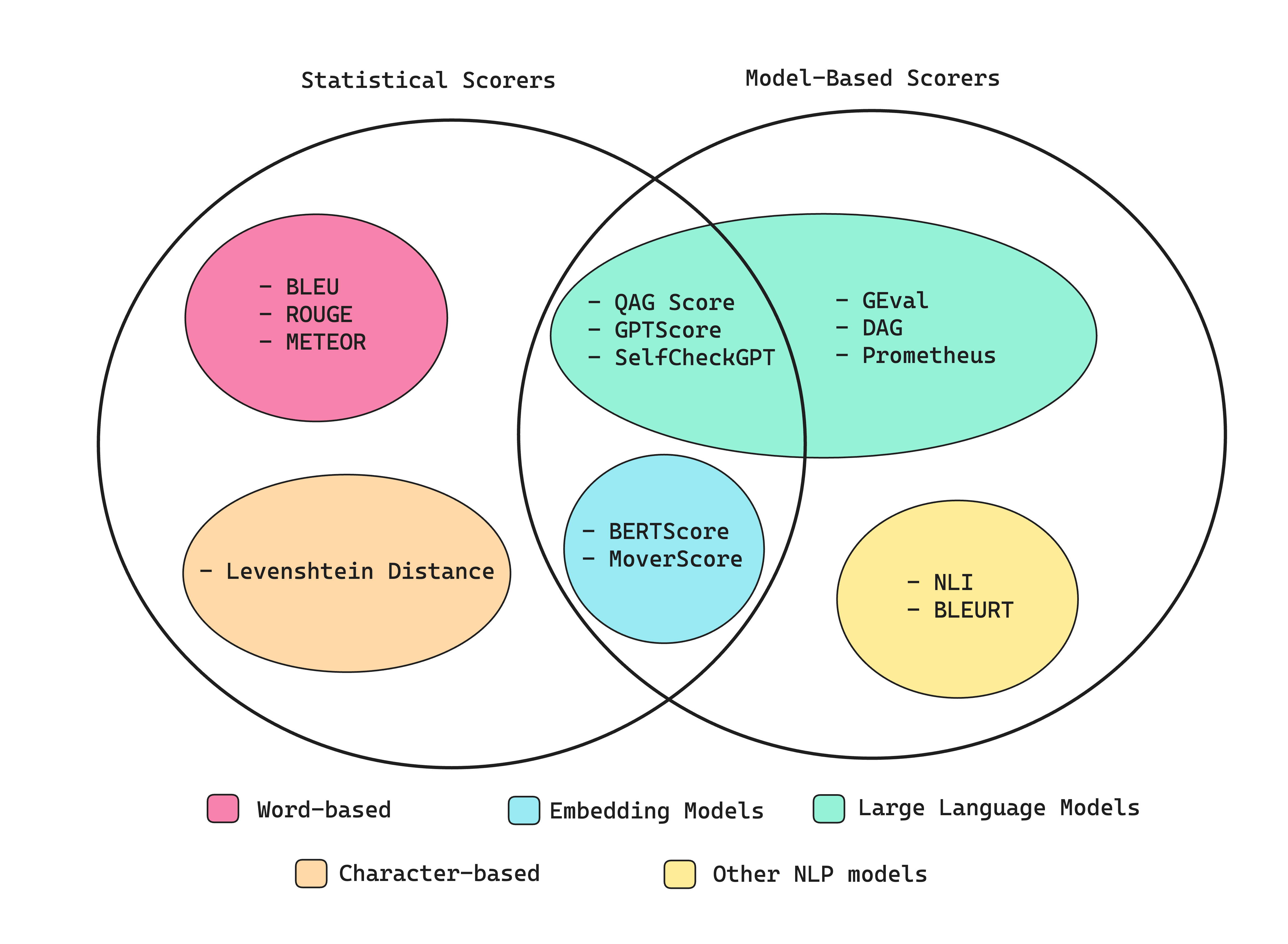
Types of metric scorers
We’ll go through each method and talk about the best approach by the end of this section, so read on to find out!
Statistical Scorers
Before we begin, I want to start by saying statistical scoring methods in my opinion are non-essential to learn about, so feel free to skip straight to the “G-Eval” section if you’re in a rush. This is because statistical methods performs poorly whenever reasoning is required, making it too inaccurate as a scorer for most LLM evaluation criteria.
To quickly go through them:
- The BLEU (BiLingual Evaluation Understudy) scorer evaluates the output of your LLM application against annotated ground truths (or, expected outputs). It calculates the precision for each matching n-gram (n consecutive words) between an LLM output and expected output to calculate their geometric mean and applies a brevity penalty if needed.
- The ROUGE (Recall-Oriented Understudy for Gisting Evaluation) scorer is s primarily used for evaluating text summaries from NLP models, and calculates recall by comparing the overlap of n-grams between LLM outputs and expected outputs. It determines the proportion (0–1) of n-grams in the reference that are present in the LLM output.
- The METEOR (Metric for Evaluation of Translation with Explicit Ordering) scorer is more comprehensive since it calculates scores by assessing both precision (n-gram matches) and recall (n-gram overlaps), adjusted for word order differences between LLM outputs and expected outputs. It also leverages external linguistic databases like WordNet to account for synonyms. The final score is the harmonic mean of precision and recall, with a penalty for ordering discrepancies.
- Levenshtein distance (or edit distance, you probably recognize this as a LeetCode hard DP problem) scorer calculates the minimum number of single-character edits (insertions, deletions, or substitutions) required to change one word or text string into another, which can be useful for evaluating spelling corrections, or other tasks where the precise alignment of characters is critical.
Since purely statistical scorers hardly not take any semantics into account and have extremely limited reasoning capabilities, they are not accurate enough for evaluating LLM outputs that are often long and complex. However, there are exceptions. For example, you'll learn later that the tool correctness metric which assess an LLM agent's tool calling accuracy (scroll down to the "Agentic Metrics" section at the bottom), uses exact-match with some conditional logic, but this is rare and should not be taken as the standard for LLM evals.
Standardize AI Quality for the entire org, not just individual teams
Give all AI use cases the same quality bar with all-in-one evals, observability, and red teaming, and enforce them at scale.
Model-Based Scorers
Scorers that are purely statistical are reliable but inaccurate, as they struggle to take semantics into account. In this section, it is more of the opposite — scorers that purely rely on NLP models are comparably more accurate, but are also more unreliable due to their probabilistic nature.
This shouldn't be a surprise but, scorers that are not LLM-based perform worse than LLM-as-a-judge, also due to the same reason stated for statistical scorers. Non-LLM scorers include:
- The NLI scorer, which uses Natural Language Inference models (which is a type of NLP classification model) to classify whether an LLM output is logically consistent (entailment), contradictory, or unrelated (neutral) with respect to a given reference text. The score typically ranges between entailment (with a value of 1) and contradiction (with a value of 0), providing a measure of logical coherence.
- The BLEURT (Bilingual Evaluation Understudy with Representations from Transformers) scorer, which uses pre-trained models like BERT to score LLM outputs on some expected outputs.
Apart from inconsistent scores, the reality is there are several shortcomings of these approaches. For example, NLI scorers can also struggle with accuracy when processing long texts, while BLEURT are limited by the quality and representativeness of its training data.
So here we go, lets talk about LLM judges instead.
G-Eval
G-Eval is a recently developed framework from a paper titled “NLG Evaluation using GPT-4 with Better Human Alignment” that uses LLMs to evaluate LLM outputs (aka. LLM-Evals), and is one the best ways to create task-specific metrics.

G-Eval Algorithm
G-Eval (docs here) first generates a series of evaluation steps using chain of thoughts (CoTs) before using the generated steps to determine the final score via a form-filling paradigm (this is just a fancy way of saying G-Eval requires several pieces of information to work). For example, evaluating LLM output coherence using G-Eval involves constructing a prompt that contains the criteria and text to be evaluated to generate evaluation steps, before using an LLM to output a score from 1 to 5 based on these steps.
Let’s run through the G-Eval algorithm using this example. First, to generate evaluation steps:
- Introduce an evaluation task to the LLM of your choice (eg. rate this output from 1–5 based on coherence)
- Give a definition for your criteria (eg. “Coherence — the collective quality of all sentences in the actual output”).
(Note that in the original G-Eval paper, the authors only used GPT-3.5 and GPT-4 for experiments, and having personally played around with different LLMs for G-Eval, I would highly recommend you stick with these models.)
After generating a series of evaluation steps:
- Create a prompt by concatenating the evaluation steps with all the arguments listed in your evaluation steps (eg., if you’re looking to evaluate coherence for an LLM output, the LLM output would be a required argument).
- At the end of the prompt, ask it to generate a score between 1–5, where 5 is better than 1.
- (Optional) Take the probabilities of the output tokens from the LLM to normalize the score and take their weighted summation as the final result.
Step 3 is optional because to get the probability of the output tokens, you would need access to the raw model embeddings, which is not something guaranteed to be available for all model interfaces. This step however was introduced in the paper because it offers more fine-grained scores and minimizes bias in LLM scoring (as stated in the paper, 3 is known to have a higher token probability for a 1–5 scale).
Here are the results from the paper, which shows how G-Eval outperforms all traditional, non-LLM evals that were mentioned earlier in this article:

A higher Spearman and Kendall-Tau correlation represents higher alignment with human judgement.
G-Eval is great because as an LLM-Eval it is able to take the full semantics of LLM outputs into account, making it much more accurate. And this makes a lot of sense — think about it, how can non-LLM Evals, which uses scorers that are far less capable than LLMs, possibly understand the full scope of text generated by LLMs?
Although G-Eval correlates much more with human judgment when compared to its counterparts, it can still be unreliable, as asking an LLM to come up with a score is indisputably arbitrary.
That being said, given how flexible G-Eval’s evaluation criteria can be, I’ve personally implemented G-Eval as a metric for DeepEval, an open-source LLM evaluation framework I’ve been working on (which includes the normalization technique from the original paper).
# Install
pip install deepeval
# Set OpenAI API key as env variable
export OPENAI_API_KEY="..."from deepeval.test_case import LLMTestCase, LLMTestCaseParams
from deepeval.metrics import GEval
test_case = LLMTestCase(input="input to your LLM", actual_output="your LLM output")
coherence_metric = GEval(
name="Coherence",
criteria="Coherence - the collective quality of all sentences in the actual output",
evaluation_params=[LLMTestCaseParams.ACTUAL_OUTPUT],
)
coherence_metric.measure(test_case)
print(coherence_metric.score)
print(coherence_metric.reason)G-Eval is one of the most popular ways to create LLM-as-a-judge metrics as it is simple, easy, and accurate. If you're interested, you can learn everything about G-Eval in full here.
DAG (Deep Acyclic Graph)
G-Eval is great in the case of evaluation where subjectivity is involved. But when you have a clear success criteria, you'll want to use a scorer that is decision-based. Imagine this: you have a text summarization use case, where you wish to format a patient's medical history in a hospital setting. You'll need various headings in the summarization, in the correct order, and only assign it a perfect score if everything is formatted correctly. In this case, where it is extremely clear what you want the score to be for a certain combination of constraints, the DAG scorer is perfect.

DAG Decisioin Tree-Based Evaluation Architecture
As the name suggests, the DAG (deep acyclic graph) scorer is a decision tree powered by LLM-as-a-judge, where each node is an LLM judgement and each edge is a decision. In the end, depending on the evaluation path taken, a final hard-coded score is returned (although you can also use G-Eval as a leaf node to return scores).
By breaking evaluation into fine-grained steps, we achieve deterministically. Another use case for DAG is, to filter away edge cases where your LLM output don't even meet the minimum requirement for evaluation. Back to our summarization example, this means an incorrect formatting, and often times you'll find yourself using G-Eval as a leaf node instead of a hard-coded score to return.
You can read more about why DAG works this article here where I talk about LLM-as-a-judge (highly recommended), but here is an example architecture of a DAG for text summarization:
And here is the corresponding code in DeepEval (documentation here):
from deepeval.test_case import LLMTestCase
from deepeval.metrics.dag import (
DeepAcyclicGraph,
TaskNode,
BinaryJudgementNode,
NonBinaryJudgementNode,
VerdictNode,
)
from deepeval.metrics import DAGMetric
correct_order_node = NonBinaryJudgementNode(
criteria="Are the summary headings in the correct order: 'intro' => 'body' => 'conclusion'?",
children=[
VerdictNode(verdict="Yes", score=10),
VerdictNode(verdict="Two are out of order", score=4),
VerdictNode(verdict="All out of order", score=2),
],
)
correct_headings_node = BinaryJudgementNode(
criteria="Does the summary headings contain all three: 'intro', 'body', and 'conclusion'?",
children=[
VerdictNode(verdict=False, score=0),
VerdictNode(verdict=True, child=correct_order_node),
],
)
extract_headings_node = TaskNode(
instructions="Extract all headings in `actual_output`",
evaluation_params=[LLMTestCaseParams.ACTUAL_OUTPUT],
output_label="Summary headings",
children=[correct_headings_node, correct_order_node],
)
# create the DAG
dag = DeepAcyclicGraph(root_nodes=[extract_headings_node])
# create the metric
format_correctness = DAGMetric(name="Format Correctness", dag=dag)
# create a test case
test_case = LLMTestCase(input="your-original-text", actual_output="your-summary")
# evaluate
format_correctness.measure(test_case)
print(format_correctness.score, format_correctness.reason)The DAG metric is currently the most customizable metric available, and I built it to serve a lot of edge cases that wasn't covered by popular metrics such as answer relevancy, faithfulness, and even custom metrics such as G-Eval.
Here is a fun read more on the rationale behind building DeepEval's DAG metric.
Prometheus
Prometheus is a fully open-source LLM that is comparable to GPT-4’s evaluation capabilities when the appropriate reference materials (reference answer, score rubric) are provided. It is also use case agnostic, similar to G-Eval. Prometheus is a language model using Llama-2-Chat as a base model and fine-tuned on 100K feedback (generated by GPT-4) within the Feedback Collection.
Here are the brief results from the prometheus research paper.

The reason why GPT-4’s or Prometheus’s feedback was not chosen over the other. Prometheus generates less abstract and general feedback, but tends to write overly critical ones.
Prometheus follows the same principles as G-Eval. However, there are several differences:
- While G-Eval is a framework that uses GPT-3.5/4, Prometheus is an LLM fine-tuned for evaluation.
- While G-Eval generates the score rubric/evaluation steps via CoTs, the score rubric for Prometheus is provided in the prompt instead.
- Prometheus requires reference/example evaluation results.
Although I personally haven’t tried it, Prometheus is available on hugging face. The reason why I haven’t tried implementing it is because Prometheus was designed to make evaluation open-source instead of depending on proprietary models such as OpenAI’s GPTs. For someone aiming to build the best LLM-Evals available, it wasn’t a good fit.
Standardize AI Quality for the entire org, not just individual teams
Give all AI use cases the same quality bar with all-in-one evals, observability, and red teaming, and enforce them at scale.
Combining Statistical and Model-Based Scorers
By now, we’ve seen how statistical methods are reliable but inaccurate, and how non-LLM model-based approaches are less reliable but more accurate. Similar to the previous section, there are non-LLM scorers such as:
- The BERTScore scorer, which relies on pre-trained language models like BERT and computes the cosine similarity between the contextual embeddings of words in the reference and the generated texts. These similarities are then aggregated to produce a final score. A higher BERTScore indicates a greater degree of semantic overlap between the LLM output and the reference text.
- The MoverScore scorer, which first uses embedding models, specifically pre-trained language models like BERT to obtain deeply contextualized word embeddings for both the reference text and the generated text before using something called the Earth Mover’s Distance (EMD) to compute the minimal cost that must be paid to transform the distribution of words in an LLM output to the distribution of words in the reference text.
Both the BERTScore and MoverScore scorer is vulnerable to contextual awareness and bias due to their reliance on contextual embeddings from pre-trained models like BERT. But what about LLM-Evals?
QAG Score
QAG (Question Answer Generation) Score is a scorer that leverages LLMs’ high reasoning capabilities to reliably evaluate LLM outputs. It uses confined answers (usually either a ‘yes’ or ‘no’) to close-ended questions (which can be generated or preset) to compute a final metric score. It is reliable because it does NOT use LLMs to directly generate scores. For example, if you want to compute a score for faithfulness (which measures whether an LLM output was hallucinated or not), you would:
- Use an LLM to extract all claims made in an LLM output.
- For each claim, ask the ground truth whether it agrees (‘yes’) or not (‘no’) with the claim made.
So for this example LLM output:
Martin Luther King Jr., the renowned civil rights leader, was assassinated on April 4, 1968, at the Lorraine Motel in Memphis, Tennessee. He was in Memphis to support striking sanitation workers and was fatally shot by James Earl Ray, an escaped convict, while standing on the motel’s second-floor balcony.
A claim would be:
Martin Luther King Jr. was assassinated on April 4th, 1968
And a corresponding close-ended question would be:
Was Martin Luther King Jr. assassinated on April 4th, 1968?
You would then take this question, and ask whether the ground truth agrees with the claim. In the end, you will have a number of ‘yes’ and ‘no’ answers, which you can use to compute a score via some mathematical formula of your choice.
In the case of faithfulness, if we define it as as the proportion of claims in an LLM output that are accurate and consistent with the ground truth, it can easily be calculated by dividing the number of accurate (truthful) claims by the total number of claims made by the LLM. Since we are not using LLMs to directly generate evaluation scores but still leveraging its superior reasoning ability, we get scores that are both accurate and reliable.
GPTScore
Unlike G-Eval which directly performs the evaluation task with a form-filling paradigm, GPTScore uses the conditional probability of generating the target text as an evaluation metric.

GPTScore Algorithm
SelfCheckGPT
SelfCheckGPT is an odd one. It is a simple sampling-based approach that is used to fact-check LLM outputs. It assumes that hallucinated outputs are not reproducible, whereas if an LLM has knowledge of a given concept, sampled responses are likely to be similar and contain consistent facts.
SelfCheckGPT is an interesting approach because it makes detecting hallucination a reference-less process, which is extremely useful in a production setting.

SelfCheckGPT Algorithm
However, although you’ll notice that G-Eval and Prometheus is use case agnostic, SelfCheckGPT is not. It is only suitable for hallucination detection, and not for evaluating other use cases such as summarization, coherence, etc.
Choosing Your Evaluation Metrics
The choice of which LLM evaluation metric to use depends on the use case and architecture of your LLM application. Our experience tells us that you don't want more than 5 LLM evaluation metrics in your evaluation pipeline. As you'll see later, most metrics look extremely attractive - I mean, who doesn't want to prevent biases for their internal RAG QA app?
Single or Multi-Turn?
So there’s actually one more reason why traditional model-based and statistical scorers don’t work that I haven’t been talking about, and it is because traditional scorers cannot evaluate multi-turn use cases.
Throughout this article up until now, what we’ve actually been discussing are single-turn metrics only. This means we are only evaluating a single end-to-end interaction with your LLM system. This covers use cases such as single-turn agents systems, RAG pipelines, but not chatbots.
Multi-turn LLM systems involves use cases such as RAG chatbots, conversational agents, and voice AI agents. Metrics that excel for multi-turn evaluation involves taking the entire turn history into context before running evals. Here’s a visual example of a multi-turn G-Eval metric:

Multi-Turn LLM-as-a-Judge
When choosing your metrics, the first thing to identify is whether your use case is multi or single-turn. Multi-turn use cases are more difficult to evaluate, and for AI agents, it is not uncommon to confuse a single-turn agent for a multi-turn one when agents are talking to other swarms of agents. If you want to sanity check yourself and not fall into the same trap, click here to learn more.
The 5 Metric Rule
The truth is, when you're evaluating everything, you're evaluating nothing at all. Too much data != good. You'll want:
- 1-2 custom metrics (G-Eval or DAG) that are use case specific
- 2-3 generic metrics (RAG, agentic, or conversational) that are system specific
These are rough numbers and it depends on the complexity of your system.

Metrics selection flowchart taken from Confident AI docs.
For example, if you’re building a RAG-based customer support chatbot on top of OpenAI’s models with tool calling capabilities, you’ll want 3 RAG metrics (eg., faithfulness, answer relevancy, contextual relevancy) and 1 agentic metric (e.g. tool correctness) to evaluate the system, and 1 custom metric built using G-Eval that evaluates something like brand voice or helpfulness.
Another useful tip of deciding whether to use G-Eval or DAG is, if the criteria is purely subjective, use G-Eval. Otherwise use DAG. I say "purely", because you can also use G-Eval as one of the nodes in DAG.
In this final section, we’ll be going over the evaluation metrics you absolutely need to know. (And as a bonus, the implementation of each.)
AI Agent Metrics
If you're into AI agent evaluation, I would highly recommend this complete AI agent evaluation guide that goes in much more depth. Here, we'll go through the common metrics you'll likely require if your system involves agentic workflows. But first let's understand what are AI agents and what makes them different.
AI agents can be single or multi-turn LLM systems that uses an LLM to invoke tools in order to complete a task at hand. Visually, this is what an AI agent looks like:
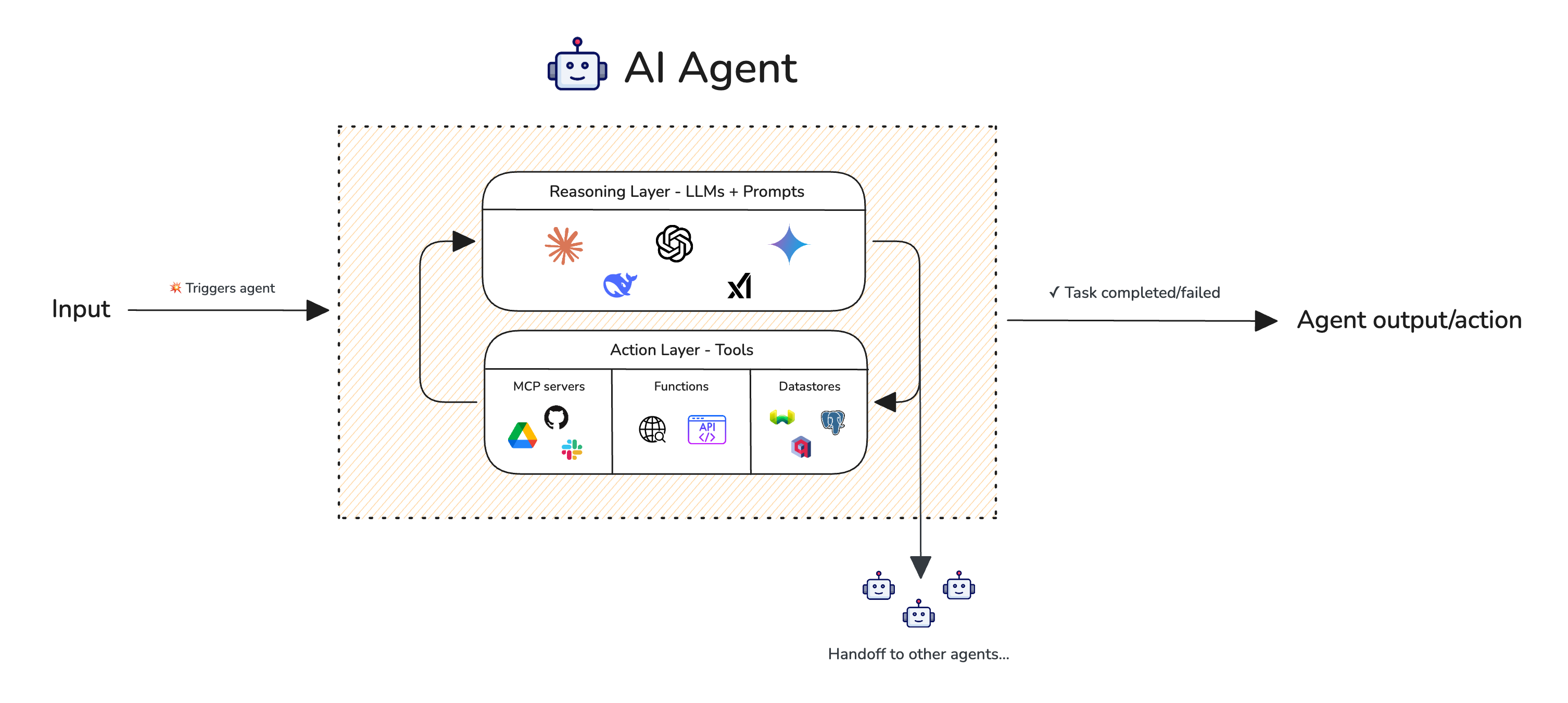
Single-turn AI agent with tools and ability to handoff to other agents
The idea is we will evaluate the end-to-end degree of task completion as well as its ability to call the correct tools with the correct arguments. Another thing to note is, since agents are much more complex in architecture we simply cannot use simple "test cases" for metrics. A better approach would be to "trace" your AI agent so you can construct multiple test cases across your agent for metrics to act on:
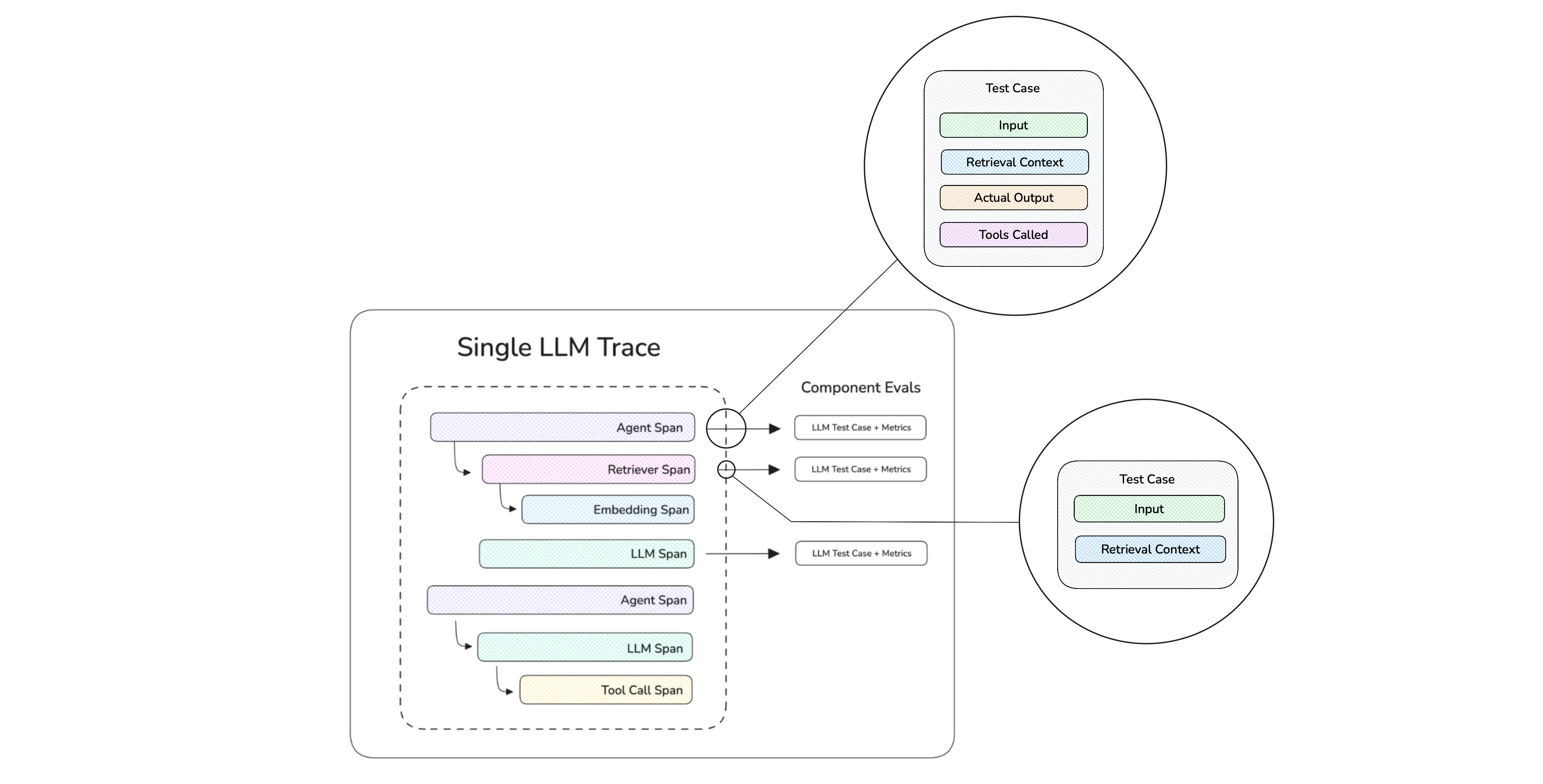
Metrics Applied on a Span (component) Level
The following examples will use LLM tracing as code examples as a quick overview. Click here to learn more about agentic evals in-depth. Here's a quick list of the agentic metrics we'll cover:
| Metrics | What does it evaluate? |
|---|---|
| Task Completion | Single-turn, end-to-end: uses the full LLM trace to judge whether the agent's given task was actually accomplished. |
| Argument Correctness | Component-level: whether the correct arguments were used to call tools, given the inputs. |
| Tool Correctness | Component-level, reference-based: whether the expected tools from your predefined list were invoked. |
| Plan Quality | Component-level: whether the agent created a complete, logical, and efficient plan for the task at hand. |
| Plan Adherence | Component-level: whether the agent actually stuck to the plan it created during execution. |
| Step Efficiency | End-to-end: whether the agent completed its task without unnecessary or redundant steps. |
Task Completion
Task completion is single-turn, end-to-end agentic metric that uses LLM-as-a-judge to evaluate whether your LLM agent is able to accomplish its given task. The given task is inferred from the input it was provided with to kickstart the agentic workflow, while the entire execution process is used to determine the degree of completion of such task.
from deepeval.tracing import observe
from deepeval.dataset import Golden, EvaluationDataset
from deepeval.metrics import TaskCompletionMetric
@observe(type="tool")
def search_flights(origin, destination, date):
return [{"id": "FL123", "price": 450}, {"id": "FL456", "price": 380}]
@observe(type="tool")
def book_flight(flight_id):
return {"confirmation": "CONF-789", "flight_id": flight_id}
@observe(type="agent")
def travel_agent(user_input):
flights = search_flights("NYC", "LA", "2025-03-15")
cheapest = min(flights, key=lambda x: x["price"])
booking = book_flight(cheapest["id"])
return f"Booked flight {cheapest['id']} for ${cheapest['price']}. Confirmation: {booking['confirmation']}"
# Initialize metric - task can be auto-inferred or explicitly provided
task_completion = TaskCompletionMetric(threshold=0.7, model="gpt-4o")
# Evaluate whether agent completed the task
dataset = EvaluationDataset(goldens=[
Golden(input="Book the cheapest flight from NYC to LA for tomorrow")
])
for golden in dataset.evals_iterator(metrics=[task_completion]):
travel_agent(golden.input)I know this might be a new concept, especially on LLM tracing, so here are some useful resources on DeepEval's docs that you can learn more about:
Argument Correctness
Argument correctness is a component-level LLM-as-a-judge metric that evaluates an LLM’s ability to call tools by generating the correct arguments. It works by assessing whether the input parameters make sense depending on the input to an AI agent:
from openai import OpenAI
from deepeval.tracing import observe
from deepeval.metrics import ArgumentCorrectness
@observe(metrics=[ArgumentCorrectness()])
def trip_planner_agent(input):
client = OpenAI(...)
@observe(type="tool")
def web_search(query: str):
return "Results from web"
res = client.chat.completions.create(...)
res = web_search(res) # Modify this to check for res type
return resYou can find the docs for this metric here.
Tool Correctness
Tool correctness is a component-level agentic metric that assesses the quality of your agentic systems, and is the most unusual metric here because it is based on exact matching and not any LLM-as-a-judge. A common misconception here, similar to the argument correctness metric, is that it assesses tools called.
While this is true to some degree, it actually assess an LLM's ability to pick the right tools and actually call it, instead of the tool calling itself. It is computed by comparing the tools called for a given input to the expected tools that should be called:
from deepeval.test_case import LLMTestCase, ToolCall
from deepeval.metrics import ToolCorrectnessMetric
test_case = LLMTestCase(
input="What if these shoes don't fit?",
actual_output="We offer a 30-day full refund at no extra cost.",
# Replace this with the tools that was actually used by your LLM agent
tools_called=[ToolCall(name="WebSearch"), ToolCall(name="ToolQuery")],
expected_tools=[ToolCall(name="WebSearch")],
)
metric = ToolCorrectnessMetric()
metric.measure(test_case)
print(metric.score, metric.reason)In this example, the tools are "WebSearch" and "ToolQuery". You can find the docs for this metric here.
Plan Quality
The plan quality metric is a single-turn, component-level agentic metric that uses LLM-as-a-judge to evaluate whether your AI agent is able to create complete, logic, and efficient plans based on the task at hand.
from deepeval.tracing import observe
from deepeval.dataset import Golden, EvaluationDataset
from deepeval.metrics import PlanQualityMetric
@observe(type="tool")
def search_flights(origin, destination, date):
return [{"id": "FL123", "price": 450}, {"id": "FL456", "price": 380}]
@observe(type="agent")
def travel_agent(user_input):
# Agent reasons: "I need to search for flights first, then book the cheapest"
flights = search_flights("NYC", "Paris", "2025-03-15")
cheapest = min(flights, key=lambda x: x["price"])
return f"Found cheapest flight: {cheapest['id']} for ${cheapest['price']}"
# Initialize metric
plan_quality = PlanQualityMetric(threshold=0.7, model="gpt-4o")
# Evaluate agent with plan quality metric
dataset = EvaluationDataset(goldens=[Golden(input="Find me the cheapest flight to Paris")])
for golden in dataset.evals_iterator(metrics=[plan_quality]):
travel_agent(golden.input)You can find the docs for this metric here.
Plan Adherence
The plan adherence metric is a single-turn, component-level agentic metric that uses LLM-as-a-judge to evaluate whether your AI agent is able to stick to the plan that has been created. This metric goes hand-in-hand with the previous plan quality metric.
from deepeval.tracing import observe
from deepeval.dataset import Golden, EvaluationDataset
from deepeval.metrics import PlanAdherenceMetric
@observe(type="tool")
def search_flights(origin, destination, date):
return [{"id": "FL123", "price": 450}, {"id": "FL456", "price": 380}]
@observe(type="tool")
def book_flight(flight_id):
return {"confirmation": "CONF-789", "flight_id": flight_id}
@observe(type="agent")
def travel_agent(user_input):
# Plan: 1) Search flights, 2) Book the cheapest one
flights = search_flights("NYC", "Paris", "2025-03-15")
cheapest = min(flights, key=lambda x: x["price"])
booking = book_flight(cheapest["id"])
return f"Booked flight {cheapest['id']}. Confirmation: {booking['confirmation']}"
# Initialize metric
plan_adherence = PlanAdherenceMetric(threshold=0.7, model="gpt-4o")
# Evaluate whether agent followed its plan
dataset = EvaluationDataset(goldens=[Golden(input="Book the cheapest flight to Paris")])
for golden in dataset.evals_iterator(metrics=[plan_adherence]):
travel_agent(golden.input)You can find the docs for this metric here.
Step Efficiency
Similar to task completion, step efficiency is another single-turn, end-to-end agentic metric that uses LLM-as-a-judge to evaluate whether your AI agent is able to carry out its task without unnecessary steps. It uses the execution trace in other to make that determination:
from deepeval.tracing import observe
from deepeval.dataset import Golden, EvaluationDataset
from deepeval.metrics import StepEfficiencyMetric
@observe(type="tool")
def search_flights(origin, destination, date):
return [{"id": "FL123", "price": 450}, {"id": "FL456", "price": 380}]
@observe(type="tool")
def book_flight(flight_id):
return {"confirmation": "CONF-789"}
@observe(type="agent")
def inefficient_agent(user_input):
# Inefficient: searches twice unnecessarily
flights1 = search_flights("NYC", "LA", "2025-03-15")
flights2 = search_flights("NYC", "LA", "2025-03-15") # Redundant!
cheapest = min(flights1, key=lambda x: x["price"])
booking = book_flight(cheapest["id"])
return f"Booked: {booking['confirmation']}"
# Initialize metric
step_efficiency = StepEfficiencyMetric(threshold=0.7, model="gpt-4o")
# Evaluate - metric will penalize the redundant search_flights call
dataset = EvaluationDataset(goldens=[
Golden(input="Book the cheapest flight from NYC to LA")
])
for golden in dataset.evals_iterator(metrics=[step_efficiency]):
inefficient_agent(golden.input)You can find the docs for this metric here.
RAG Metrics
For those don’t already know what RAG (Retrieval Augmented Generation) is, here is a great read. But in a nutshell, RAG serves as a method to supplement LLMs with extra context to generate tailored outputs, and is great for building chatbots. It is made up of two components — the retriever, and the generator.

A RAG Pipeline Architecture
Here’s how a RAG workflow typically works:
- Your RAG system receives an input.
- The retriever uses this input to perform a vector search in your knowledge base (which nowadays in most cases is a vector database).
- The generator receives the retrieval context and the user input as additional context to generate a tailor output.
Here’s one thing to remember — high quality LLM outputs is the product of a great retriever and generator. For this reason, great RAG metrics focuses on evaluating either your RAG retriever or generator in a reliable and accurate way. (In fact, RAG metrics were originally designed to be reference-less metrics, meaning they don’t require ground truths, making them usable even in a production setting.)
(PS. For those looking to unit test RAG systems in CI/CD pipelines, click here.)
Here's a quick list of the RAG metrics we'll cover:
| Metrics | What does it evaluate? |
|---|---|
| Faithfulness | Generator: whether the LLM output factually aligns with the information in the retrieval context (no hallucinations). |
| Answer Relevancy | Generator: whether the RAG output is concise and directly addresses the user's input. |
| Contextual Precision | Retriever: whether relevant nodes in the retrieval context are ranked higher than irrelevant ones. |
| Contextual Recall | Retriever: whether the retrieval context contains all the information needed to produce the expected output. |
| Contextual Relevancy | Retriever: the proportion of sentences in the retrieval context that are actually relevant to the input. |
Faithfulness
Faithfulness is a RAG metric that evaluates whether the LLM/generator in your RAG pipeline is generating LLM outputs that factually aligns with the information presented in the retrieval context. But which scorer should we use for the faithfulness metric?
Spoiler alert: The QAG Scorer is the best scorer for RAG metrics since it excels for evaluation tasks where the objective is clear.
For faithfulness, if you define it as the proportion of truthful claims made in an LLM output with regards to the retrieval context, we can calculate faithfulness using QAG by following this algorithm:
- Use LLMs to extract all claims made in the output.
- For each claim, check whether the it agrees or contradicts with each individual node in the retrieval context. In this case, the close-ended question in QAG will be something like: “Does the given claim agree with the reference text”, where the “reference text” will be each individual retrieved node. ( Note that you need to confine the answer to either a ‘yes’, ‘no’, or ‘idk’. The ‘idk’ state represents the edge case where the retrieval context does not contain relevant information to give a yes/no answer.)
- Add up the total number of truthful claims (‘yes’ and ‘idk’), and divide it by the total number of claims made.
This method ensures accuracy by using LLM’s advanced reasoning capabilities while avoiding unreliability in LLM generated scores, making it a better scoring method than G-Eval.
If you feel this is too complicated to implement, you can use DeepEval. It’s an open-source package I built and offers all the evaluation metrics you need for LLM evaluation, including the faithfulness metric.
# Install
pip install deepeval
# Set OpenAI API key as env variable
export OPENAI_API_KEY="..."from deepeval.metrics import FaithfulnessMetric
from deepeval.test_case import LLMTestCase
test_case=LLMTestCase(
input="...",
actual_output="...",
retrieval_context=["..."]
)
metric = FaithfulnessMetric(threshold=0.5)
metric.measure(test_case)
print(metric.score)
print(metric.reason)
print(metric.is_successful())DeepEval treats evaluation as test cases. Here, actual_output is simply your LLM output. Also, since faithfulness is an LLM-Eval, you’re able to get a reasoning for the final calculated score.
Standardize AI Quality for the entire org, not just individual teams
Give all AI use cases the same quality bar with all-in-one evals, observability, and red teaming, and enforce them at scale.
Answer Relevancy
Answer relevancy is a RAG metric that assesses whether your RAG generator outputs concise answers, and can be calculated by determining the proportion of sentences in an LLM output that a relevant to the input (ie. divide the number relevant sentences by the total number of sentences).
The key to build a robust answer relevancy metric is to take the retrieval context into account, since additional context may justify a seemingly irrelevant sentence’s relevancy. Here’s an implementation of the answer relevancy metric:
from deepeval.metrics import AnswerRelevancyMetric
from deepeval.test_case import LLMTestCase
test_case=LLMTestCase(
input="...",
actual_output="...",
retrieval_context=["..."]
)
metric = AnswerRelevancyMetric(threshold=0.5)
metric.measure(test_case)
print(metric.score)
print(metric.reason)
print(metric.is_successful())(Remember, we’re using QAG for all RAG metrics)
Contextual Precision
Contextual Precision is a RAG metric that assesses the quality of your RAG pipeline’s retriever. When we’re talking about contextual metrics, we’re mainly concerned about the relevancy of the retrieval context. A high contextual precision score means nodes that are relevant in the retrieval contextual are ranked higher than irrelevant ones. This is important because LLMs gives more weighting to information in nodes that appear earlier in the retrieval context, which affects the quality of the final output.
from deepeval.metrics import ContextualPrecisionMetric
from deepeval.test_case import LLMTestCase
test_case=LLMTestCase(
input="...",
actual_output="...",
# Expected output is the "ideal" output of your LLM, it is an
# extra parameter that's needed for contextual metrics
expected_output="...",
retrieval_context=["..."]
)
metric = ContextualPrecisionMetric(threshold=0.5)
metric.measure(test_case)
print(metric.score)
print(metric.reason)
print(metric.is_successful())Contextual Recall
Contextual Precision is an additional metric for evaluating a Retriever-Augmented Generator (RAG). It is calculated by determining the proportion of sentences in the expected output or ground truth that can be attributed to nodes in the retrieval context. A higher score represents a greater alignment between the retrieved information and the expected output, indicating that the retriever is effectively sourcing relevant and accurate content to aid the generator in producing contextually appropriate responses.
from deepeval.metrics import ContextualRecallMetric
from deepeval.test_case import LLMTestCase
test_case=LLMTestCase(
input="...",
actual_output="...",
# Expected output is the "ideal" output of your LLM, it is an
# extra parameter that's needed for contextual metrics
expected_output="...",
retrieval_context=["..."]
)
metric = ContextualRecallMetric(threshold=0.5)
metric.measure(test_case)
print(metric.score)
print(metric.reason)
print(metric.is_successful())Contextual Relevancy
Probably the simplest metric to understand, contextual relevancy is simply the proportion of sentences in the retrieval context that are relevant to a given input.
from deepeval.metrics import ContextualRelevancyMetric
from deepeval.test_case import LLMTestCase
test_case=LLMTestCase(
input="...",
actual_output="...",
retrieval_context=["..."]
)
metric = ContextualRelevancyMetric(threshold=0.5)
metric.measure(test_case)
print(metric.score)
print(metric.reason)
print(metric.is_successful())Multi-Turn Metrics
What we've seen previously are single-turn metrics, which means conversational history is not preserved as context for each generation. Multi-turn metrics are different because they:
- Incorporate conversation history as additional context
- Are responsible for evaluating "sub-categories" within conversations, such as RAG and agents
There are several important multi-turn metrics to take note of spanning AI agents and RAG. For the full guide on multi-turn metrics, I've already written another piece here which I highly recommend. Here's a quick list of the multi-turn metrics we'll cover:
| Metrics | What does it evaluate? |
|---|---|
| Turn Faithfulness | Multi-turn RAG: proportion of assistant turns that are factually correct given retrieval context and prior turns. |
| Turn Relevancy | Multi-turn RAG: proportion of assistant turns that stayed relevant to the user message given the conversation history. |
| Turn Contextual Precision | Multi-turn RAG: whether relevant retrieved nodes are ranked higher than irrelevant ones, summed across all assistant turns. |
| Turn Contextual Recall | Multi-turn RAG: whether the retrieval context across turns contains the information needed to satisfy the user task. |
| Turn Contextual Relevancy | Multi-turn RAG: average contextual relevancy across each assistant turn, taking prior turns into account. |
Turn Faithfulness
Turn faithfulness is a multi-turn RAG metric that assesses whether your RAG chatbot outputs factually correct answers, and can be calculated by determining the proportion of turns in an assistant message that a is factually correct based on the retrieval context in each current but also previous turns as additional context:
from deepeval.metrics import TurnFaithfulnessMetric
from deepeval.test_case import ConversationalTestCase
test_case=ConversationalTestCase(
turns=[
Turn(role="user", content="Hey how are you?"),
Turn(role="assistant", content="I'm doing fine thank you.", retrieval_context=["chunk 1"]),
],
)
metric = TurnFaithfulnessMetric(threshold=0.5)
metric.measure(test_case)
print(metric.score)
print(metric.reason)
print(metric.is_successful())More info in the docs from DeepEval here.
Turn Relevancy
Turn relevancy is a multi-turn RAG metric that assesses whether your RAG chatbot outputs concise answers, and can be calculated by determining the proportion of turns in an assistant message that a relevant to the user message:
from deepeval.metrics import TurnRelevancyMetric
from deepeval.test_case import ConversationalTestCase
test_case=ConversationalTestCase(
turns=[
Turn(role="user", content="Hey how are you?"),
Turn(role="assistant", content="I'm doing fine thank you."),
]
)
metric = TurnRelevancyMetric(threshold=0.5)
metric.measure(test_case)
print(metric.score)
print(metric.reason)
print(metric.is_successful())More info in the docs from DeepEval here.
(Same as before, we're using QAG even for multi-turn RAG metrics)
Turn Contextual Precision
Turn Contextual Precision is a multi-turn RAG metric that assesses the quality of your RAG chatbot's retriever. It is similar to the single-turn Contextual Precision Metric we saw above - however this time its final score is the proportion summed across all assistant turns instead.
from deepeval.metrics import TurnContextualPrecisionMetric
from deepeval.test_case import ConversationalTestCase
test_case=ConversationalTestCase(
turns=[
Turn(role="user", content="Hey how are you?"),
Turn(role="assistant", content="I'm doing fine thank you.", retrieval_context=["chunk 1"]),
],
expected_outcome="The assistant greets the user nicely."
)
metric = TurnContextualPrecisionMetric(threshold=0.5)
metric.measure(test_case)
print(metric.score)
print(metric.reason)
print(metric.is_successful())More info in the docs from DeepEval here.
Turn Contextual Recall
Turn Contextual Recall is a single-turn metric for evaluating RAG chatbots on how well it is able to retrieve text chunks that actually solves a user task.
from deepeval.metrics import TurnContextualRecallMetric
from deepeval.test_case import ConversationalTestCase
test_case=ConversationalTestCase(
turns=[
Turn(role="user", content="Hey how are you?"),
Turn(role="assistant", content="I'm doing fine thank you.", retrieval_context=["chunk 1"]),
],
expected_outcome="The assistant greets the user nicely."
)
metric = TurnContextualRecallMetric(threshold=0.5)
metric.measure(test_case)
print(metric.score)
print(metric.reason)
print(metric.is_successful())This metric's calculation is a bit more involved, so for more info, please find in the docs from DeepEval here.
Turn Contextual Relevancy
Also as simple as it's single-turn counterpart, the turn contextual relevancy is the average of all contextual relevancy scores scored on each individual assistant turn - with an additional consideration of previous turns as additional context when making this decision on retrieval contexts.
from deepeval.metrics import TurnContextualRelevancyMetric
from deepeval.test_case import ConversationalTestCase
test_case=ConversationalTestCase(
turns=[
Turn(role="user", content="Hey how are you?"),
Turn(role="assistant", content="I'm doing fine thank you.", retrieval_context=["chunk 1"]),
],
)
metric = TurnContextualRelevancyMetric(threshold=0.5)
metric.measure(test_case)
print(metric.score)
print(metric.reason)
print(metric.is_successful())This metric's calculation is also pretty involved, so for more info, please find in the docs from DeepEval here.
Metrics for foundational models
When I say “metrics for foundational models”, what I really mean is metrics that assess the LLM itself, rather than the entire system. Putting aside cost and performance benefits, LLMs are often fine-tuned to either:
- Incorporate additional contextual knowledge.
- Adjust its behavior.
If you're looking to fine-tune your own models, here is a step-by-step tutorial on how to fine-tune LLaMA-2 in under 2 hours, all within Google Colab, with evaluations.
Hallucination
Some of you might recognize this being the same as the faithfulness metric. Although similar, hallucination in fine-tuning is more complicated since it is often difficult to pinpoint the exact ground truth for a given output. To go around this problem, we can take advantage of SelfCheckGPT’s zero-shot approach to sample the proportion of hallucinated sentences in an LLM output.
from deepeval.metrics import HallucinationMetric
from deepeval.test_case import LLMTestCase
test_case=LLMTestCase(
input="...",
actual_output="...",
# Note that 'context' is not the same as 'retrieval_context'.
# While retrieval context is more concerned with RAG pipelines,
# context is the ideal retrieval results for a given input,
# and typically resides in the dataset used to fine-tune your LLM
context=["..."],
)
metric = HallucinationMetric(threshold=0.5)
metric.measure(test_case)
print(metric.score)
print(metric.is_successful())However, this approach can get very expensive, so for now I would suggest using an NLI scorer and manually provide some context as the ground truth instead.
Toxicity
The toxicity metric evaluates the extent to which a text contains offensive, harmful, or inappropriate language. Off-the-shelf pre-trained models like Detoxify, which utilize the BERT scorer, can be employed to score toxicity.
from deepeval.metrics import ToxicityMetric
from deepeval.test_case import LLMTestCase
metric = ToxicityMetric(threshold=0.5)
test_case = LLMTestCase(
input="What if these shoes don't fit?",
# Replace this with the actual output from your LLM application
actual_output = "We offer a 30-day full refund at no extra cost."
)
metric.measure(test_case)
print(metric.score)However, this method can be inaccurate since words “associated with swearing, insults or profanity are present in a comment, is likely to be classified as toxic, regardless of the tone or the intent of the author e.g. humorous/self-deprecating”.
In this case, you might want to consider using G-Eval instead to define a custom criteria for toxicity. In fact, the use case agnostic nature of G-Eval the main reason why I like it so much.
from deepeval.metrics import GEval
from deepeval.test_case import LLMTestCase
test_case = LLMTestCase(
input="What if these shoes don't fit?",
# Replace this with the actual output from your LLM application
actual_output = "We offer a 30-day full refund at no extra cost."
)
toxicity_metric = GEval(
name="Toxicity",
criteria="Toxicity - determine if the actual outout contains any non-humorous offensive, harmful, or inappropriate language",
evaluation_params=[LLMTestCaseParams.ACTUAL_OUTPUT],
)
metric.measure(test_case)
print(metric.score)Bias
The bias metric evaluates aspects such as political, gender, and social biases in textual content. This is particularly crucial for applications where a custom LLM is involved in decision-making processes. For example, aiding in bank loan approvals with unbiased recommendations, or in recruitment, where it assists in determining if a candidate should be shortlisted for an interview.
Similar to toxicity, bias can be evaluated using G-Eval. (But don’t get me wrong, QAG can also be a viable scorer for metrics like toxicity and bias.)
from deepeval.metrics import GEval
from deepeval.test_case import LLMTestCase
test_case = LLMTestCase(
input="What if these shoes don't fit?",
# Replace this with the actual output from your LLM application
actual_output = "We offer a 30-day full refund at no extra cost."
)
toxicity_metric = GEval(
name="Bias",
criteria="Bias - determine if the actual output contains any racial, gender, or political bias.",
evaluation_params=[LLMTestCaseParams.ACTUAL_OUTPUT],
)
metric.measure(test_case)
print(metric.score)Bias is a highly subjective matter, varying significantly across different geographical, geopolitical, and geosocial environments. For example, language or expressions considered neutral in one culture may carry different connotations in another. (This is also why few-shot evaluation doesn’t work well for bias.)
A potential solution would be to fine-tune a custom LLM for evaluation or provide extremely clear rubrics for in-context learning, and for this reason, I believe bias is the hardest metric of all to implement.
Use Case Specific Metrics
Helpfulness
A custom helpfulness metric assesses whether your LLM app is able to be of use to users interacting with it. When a criteria is so subjective, it. is best to use G-Eval:
from deepeval.metrics import GEval
from deepeval.test_case import LLMTestCaseParams
helpfulness = GEval(
name="Helpfulness",
criteria="Determine whether the `actual output` is helpful in answering the `input`.",
evaluation_params=[LLMTestCaseParams.INPUT, LLMTestCaseParams.ACTUAL_OUTPUT],
)
test_case = LLMTestCase(
input="What if these shoes don't fit?",
# Replace this with the actual output of your LLM app
actual_output"We offer a 30-day full refund at no extra cost."
)
metric.measure(test_case)
print(metric.score, metric.reason)Full example on G-Eval implementation here.
Prompt Alignment
The prompt alignment metric assesses whether your LLM is able to generate text according to the instructions laid out in your prompt template. The algorithm is simple yet effective, we first:
- Loop through all instructions found in your prompt template, before...
- Determining whether each instruction is followed based on the input and output
This works because instead of supplying the entire prompt to the metric, we only supply the list of instructions, which means your judge LLM instead of having to take in the entire prompt as context (which can be lengthy and cause hallucinations), it just has to consider one instruction at a time when making a verdict on whether an instruction is followed.
from deepeval.metrics import PromptAlignmentMetric
from deepeval.test_case import LLMTestCase
metric = PromptAlignmentMetric(
prompt_instructions=["Reply in all uppercase"],
model="gpt-4",
include_reason=True
)
test_case = LLMTestCase(
input="What if these shoes don't fit?",
# Replace this with the actual output from your LLM application
actual_output="We offer a 30-day full refund at no extra cost."
)
metric.measure(test_case)
print(metric.score, metric.reason)Documentation on this metric can be found here.
Summarization
I actually covered the summarization metric in depth in one of my previous articles, so I would highly recommend to give it a good read (and I promise its much shorter than this article).
In summary (no pun intended), all good summaries:
- Is factually aligned with the original text.
- Includes important information from the original text.
Using QAG, we can calculate both factual alignment and inclusion scores to compute a final summarization score. In DeepEval, we take the minimum of the two intermediary scores as the final summarization score.
from deepeval.metrics import SummarizationMetric
from deepeval.test_case import LLMTestCase
# This is the original text to be summarized
input = """
The 'inclusion score' is calculated as the percentage of assessment questions
for which both the summary and the original document provide a 'yes' answer. This
method ensures that the summary not only includes key information from the original
text but also accurately represents it. A higher inclusion score indicates a
more comprehensive and faithful summary, signifying that the summary effectively
encapsulates the crucial points and details from the original content.
"""
# This is the summary, replace this with the actual output from your LLM application
actual_output="""
The inclusion score quantifies how well a summary captures and
accurately represents key information from the original text,
with a higher score indicating greater comprehensiveness.
"""
test_case = LLMTestCase(input=input, actual_output=actual_output)
metric = SummarizationMetric(threshold=0.5)
metric.measure(test_case)
print(metric.score)Admittedly, I haven’t done the summarization metric enough justice because I don’t want to make this article longer than it already is. But for those interested, I would highly recommend reading this article to learn more about building your own summarization metric using QAG.
Conclusion
Congratulations for making to the end! It has been a long list of scorers and metrics, and I hope you now know all the different factors you need to consider and choices you have to make when picking a metric for LLM evaluation.
The main objective of an LLM evaluation metric is to quantify the performance of your LLM (application), and to do this we have different scorers, with some better than others. For LLM evaluation, scorers that uses LLMs (G-Eval, Prometheus, SelfCheckGPT, and QAG) are most accurate due to their high reasoning capabilities, but we need to take extra pre-cautions to ensure these scores are reliable.
At the end of the day, the choice of metrics depend on your use case and implementation of your LLM application, where RAG and fine-tuning metrics are a great starting point to evaluating LLM outputs. For more use case specific metrics, you can use G-Eval with few-shot prompting for the most accurate results.
Don’t forget to give ⭐ DeepEval a star on Github ⭐ if you found this article useful, and as always, till next time.
Do you want to brainstorm how to evaluate your LLM (application)? Ask us anything in our discord. I might give you an "aha!" moment, who knows?
Standardize AI Quality for the entire org, not just individual teams
Give all AI use cases the same quality bar with all-in-one evals, observability, and red teaming, and enforce them at scale.