Stay Confident
Subscribe to our weekly newsletter to stay confident in the AI systems you build.
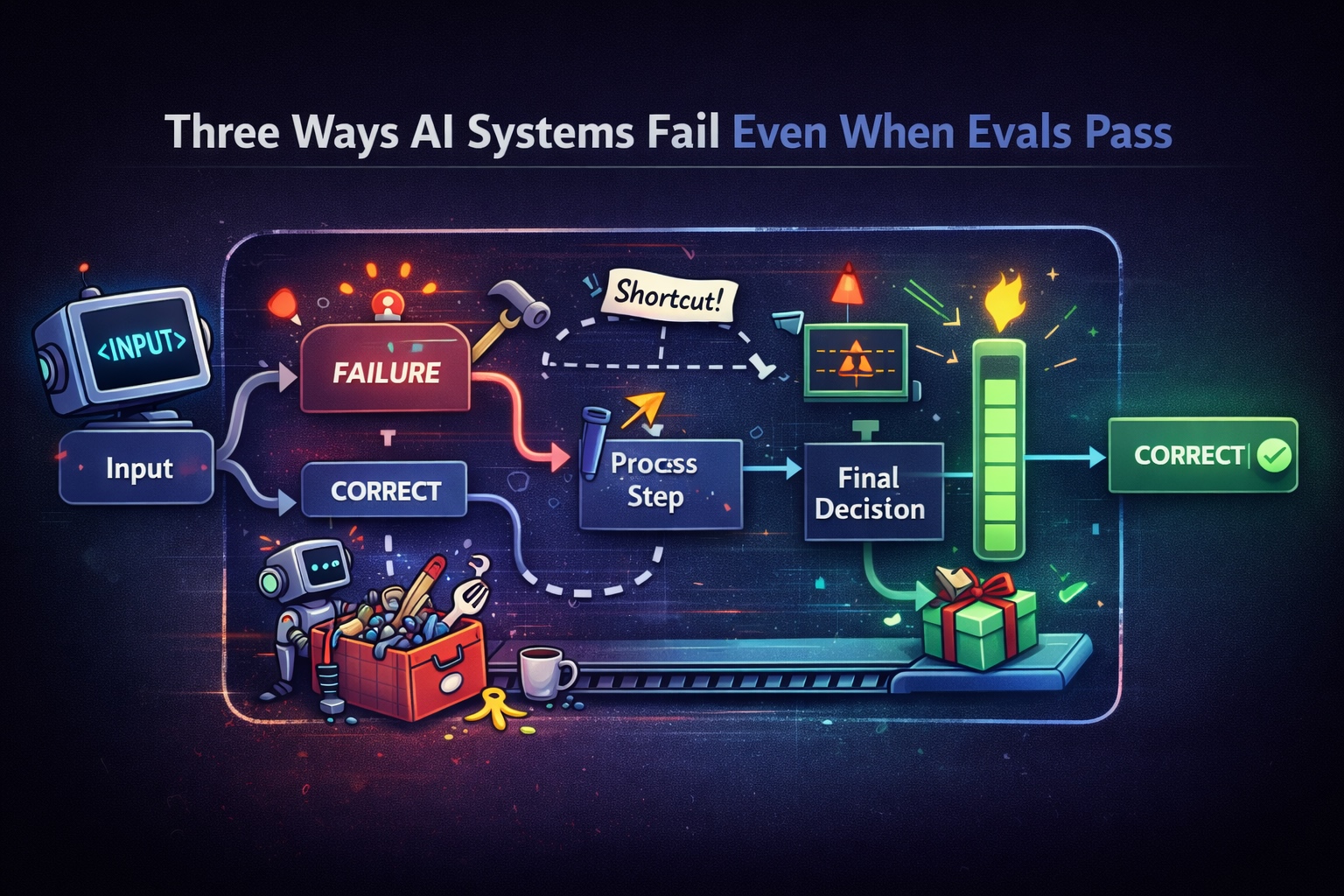
Three Ways AI Systems Fail Even When Evals Pass
AI systems can pass evals while still behaving incorrectly. This post explores three common failure modes that slip through output-based evaluation.

Brian Neville-O'Neill
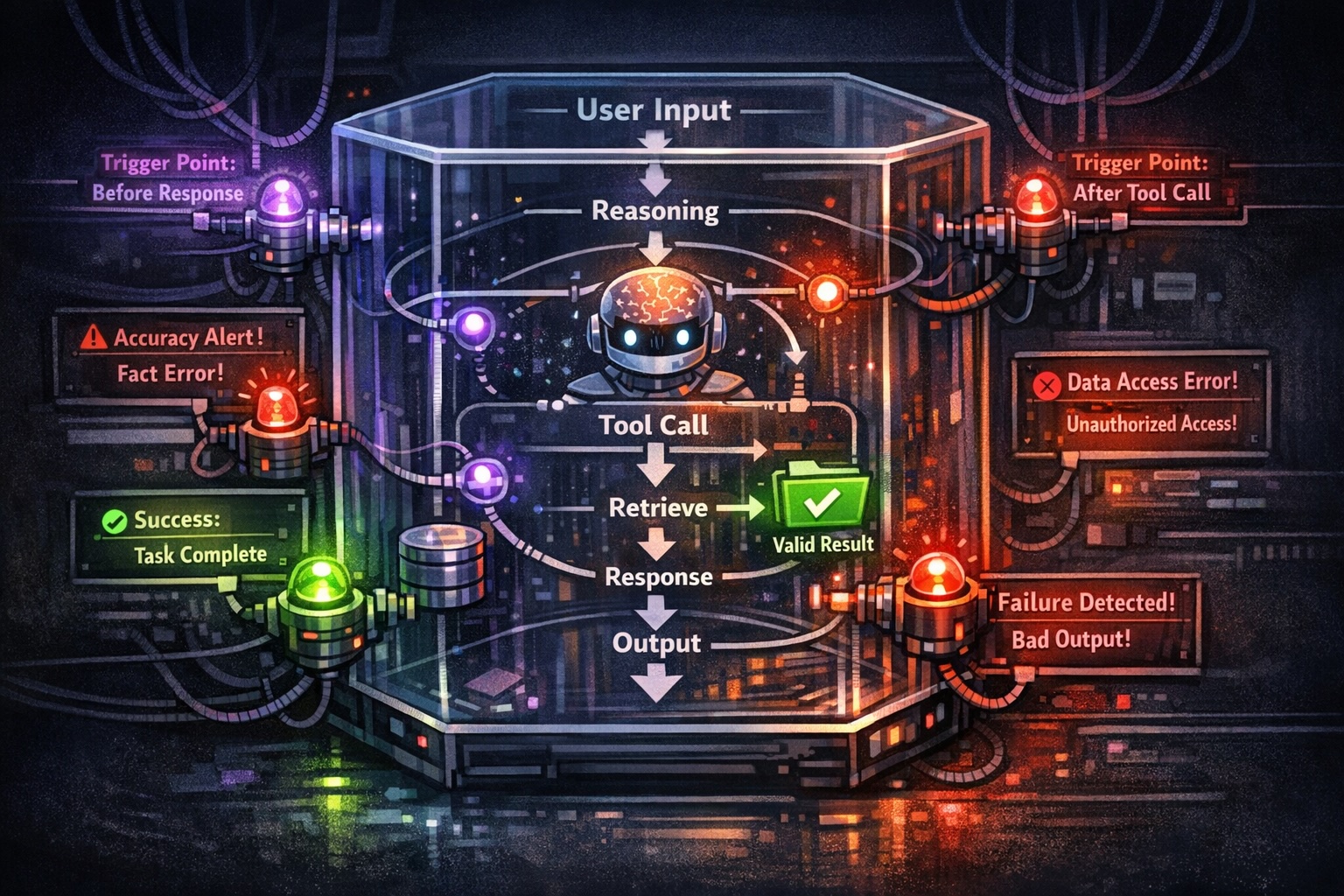
Your AI Agent Passed Evals. That’s the Problem.
Passing evals doesn't mean your AI agent works — it means your tests missed how it fails. Why output-based evals create false confidence and what to measure instead.
Brian Neville-O'Neill
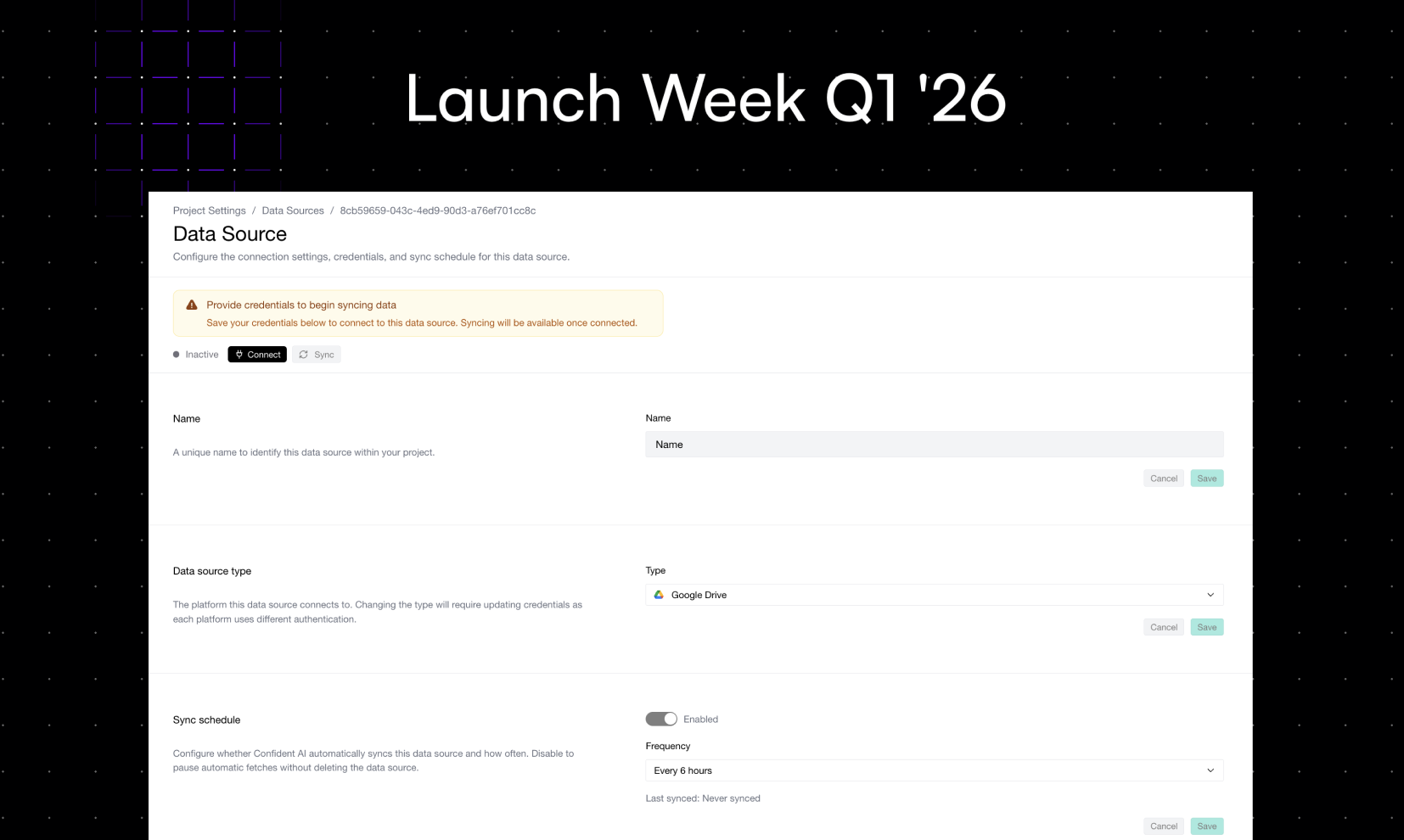
Launch Week Day 5 (5/5): Generate Datasets from Your Data Sources
Your best evaluation data already exists — it's sitting in Google Drive, SharePoint, Notion, and S3. Dataset generation on Confident AI turns your existing documents into evaluation-ready datasets automatically.

Jeffrey Ip

Launch Week Day 4 (4/5): Auto-Categorize Traces & Threads
You can't improve what you can't see. Auto-categorization tells you what your users are actually asking, detects response drift, and shows you which categories perform best — and which ones need help.
Jeffrey Ip

Launch Week Day 3 (3/5): Auto-Ingest Traces into Datasets & Annotation Queues
Production traces are the best dataset you’ll ever get — but most teams never turn them into one. With auto-ingest, your traces flow straight into datasets and annotation queues, continuously.

Brian Romain
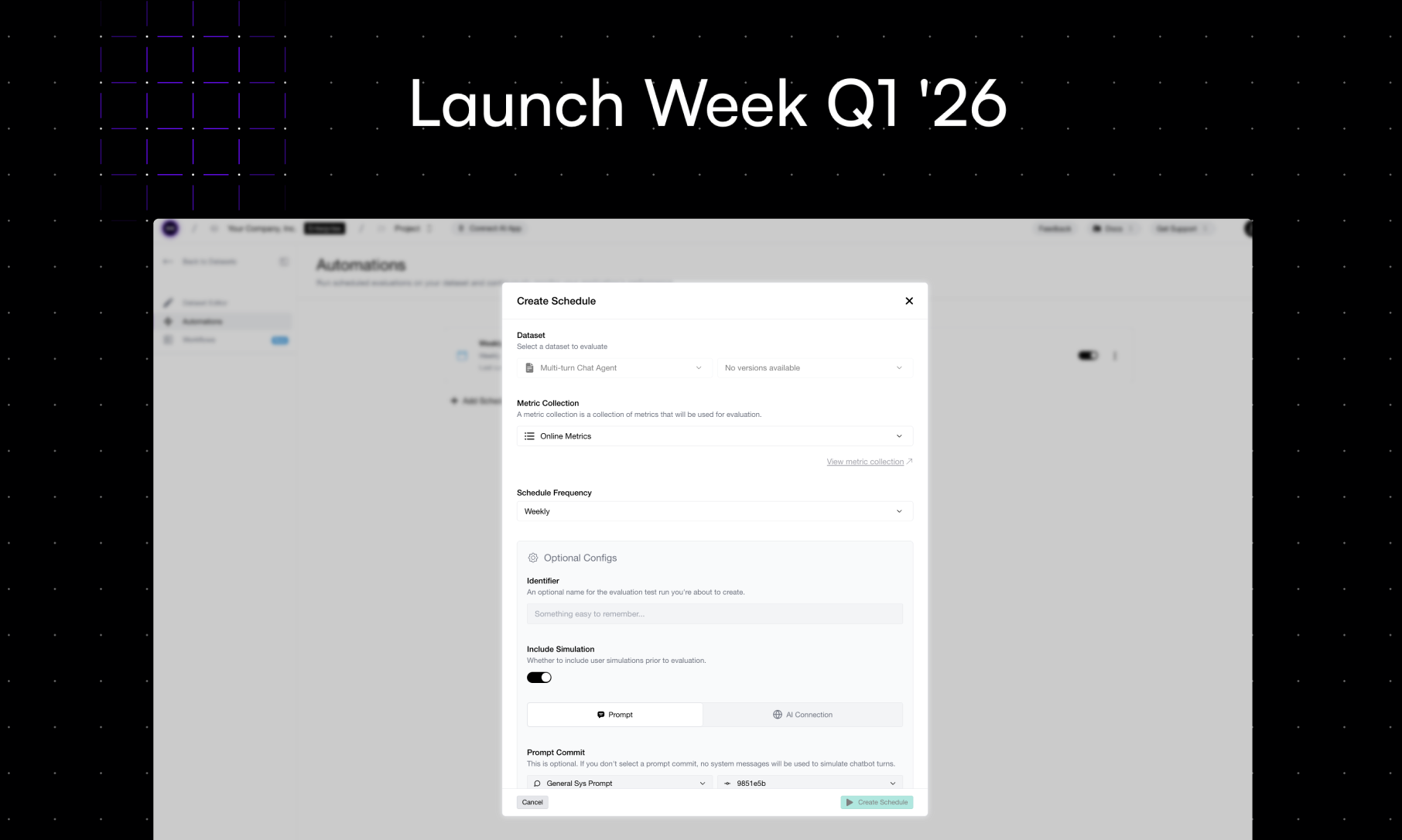
Launch Week Day 2 (2/5): Scheduled Evals
Everyone agrees evals should run regularly. But nobody remembers to actually run them. Scheduled Evals fixes that — set the frequency, configure your mappings, and never scramble before a release again.

Kritin Vongthongsri

Announcing Launch Week Q1 '26! Day 1: Automated Error Analysis
Error analysis used to mean pulling traces in code, hacking together an LLM to recommend metrics, and hoping for the best. Confident AI now does it for you.
Jeffrey Ip

Multi-Turn LLM Evaluation in 2026: What You Need to Know
In this article, I'll break down multi-turn LLM evaluation — how it differs from single-turn, what metrics actually matter, and how to implement it.
Jeffrey Ip

The Step-By-Step Guide to MCP Evaluation
A step-by-step guide to MCP evaluation: how to test MCP-based LLM apps and agents, measure tool use and task completion, and catch failures with DeepEval.

Cale

AI Agent Evaluation: Metrics, Traces, Human Review, and Workflows
A practical guide to evaluating AI agents with LLM metrics and tracing—plus when human review matters, how it calibrates judges, and workflows that combine CI, sampling, and production signals.