



LLM-as-a-Judge Metrics
Understanding everything you need to know about LLM-as-a-Judge
Overview
LLM-as-a-Judge refers to using large language models (LLMs) to evaluate the outputs of other LLM systems. This approach enables scalable, cost-effective, and human-like assessment. It is:
- More effective than traditional metrics such as BLEU or ROUGE
- Faster than manual human evaluation
- More reliable and consistent than human annotators
This technique works by crafting a rubric or evaluation prompt, feeding it alongside the input and output to a secondary LLM (“judge”), and having it return a quality score or decision.
What is LLM-as-a-Judge?
LLM-as-a-Judge uses a dedicated LLM to grade or assess generated LLM outputs. You define a scoring criterion via an evaluation prompt, then the judge examines the input and output to assign a score or label based on that rubric.
Evaluation Prompt:
You are an expert judge. Your task is to rate how relevant the following response is based on the provided input. Rate on a scale from 1 to 5, where:
1 = Completely irrelevant
2 = Mostly irrelevant
3 = Somewhat relevant but with noticeable issues
4 = Mostly relevant with minor issues
5 = Fully correct and accurate
Input:
{input}
LLM Response:
{output}
Please return only the numeric score (1 to 5) and no explanation.
Score:This technique, when done correctly, has shown to exhibit a higher alignment rate than humans (81%) as shown in the "Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena" paper, which was also the first paper that introduced LLM-as-a-Judge.
Two Types of Judges
In the section above, we actually saw a system prompt for evaluating single-turn LLM interactions. However, LLM-as-a-judge has two main types:
Single-Output
- Evaluates LLM output based on a single interaction
- Outputs numerical scores (e.g., 1-5 scale) for quantitative analysis
- Can be referenceless (no expected output) or reference-based
- Perfect for regression testing and production online evaluations
Suitable for: Most evaluation scenarios, especially when you need quantitative scores
Pairwise Comparison
- Compares two responses to determine which is better
- Outputs qualitative decisions (A, B, or Tie) rather than scores
- Requires multiple LLM versions to run simultaneously
- Less common due to complexity and lack of quantitative output
Suitable for: A/B testing scenarios where direct comparison is needed
Single-output
Single-output LLM-as-a-judge refers to evaluating an LLM output based solely on a single interaction at hand, which are represented in your evaluation prompt template. These can either be referenceless or reference-based.
Refernceless
Referenceless single-output judges simply means there are no labelled, expected output/outcome for your LLM judge to anchor as the ideal output. This is perfect for those that:
- Don't have access to expected output/outcomes, such as in production environments where you wish to run online evals
- Have trouble curating expected outputs/outcomes
Reference-based
Reference-based single-output judging gives better reliability, and also helps teams anchor towards what an ideal output/outcome should look like. Often times the only addition to the evaluation prompt is an additional expected output variable:
You are an expert judge. Your task is to rate how relevant the following response is based on the provided input. Rate on a scale from 1 to 5, where:
1 = Completely irrelevant
2 = Mostly irrelevant
3 = Somewhat relevant but with noticeable issues
4 = Mostly relevant with minor issues
5 = Fully correct and accurate
Input:
{input}
Expected Output:
{expected_output}
LLM Response:
{output}
Please return only the numeric score (1 to 5) and no explanation.
Score:Pairwise comparison
Unlike single-output, pairwise LLM-as-a-judge is much less common because they:
- Don't output a score, meaning are less quantitative for score analysis
- Require multiple versions of your LLM to run at once, which can be challenging
Essentially, instead of outputting a score pairwise comparison aims to pick the best output/outcome based on a custom rubric at hand. The prompt template looks something more like this:
You are an expert judge. Your task is to compare two responses to the same input and decide which one is better based on relevance and accuracy.
Guidelines:
Choose Response A if it is clearly better.
Choose Response B if it is clearly better.
If both are equally good (or equally poor), choose Tie.
Input:
{input}
Expected Output (reference, if helpful):
{expected_output}
Response A:
{output_a}
Response B:
{output_b}
Please return only one of the following:
- A
- B
- Tie
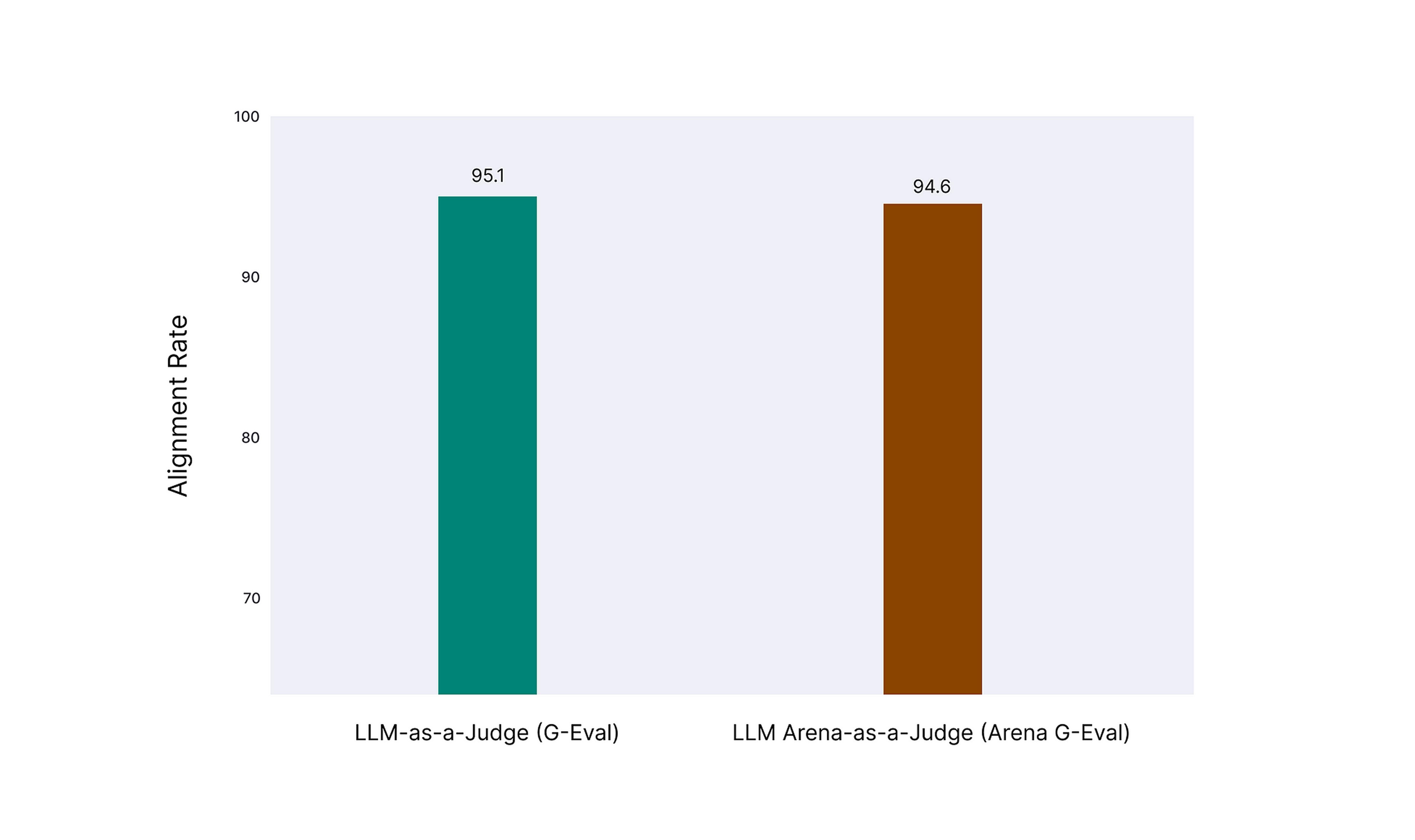
Decision:In Confident AI, out of the 40+ LLM evaluation metrics, only the Arena G-Eval metric uses pairwise comparison. However, an internal benchmarking of deepeval's Arena G-Eval metric shows nearly identical performance to reference-less single-output LLM-as-a-judge:
Single vs Multi-turn
Scoring single-turn LLM apps are straightforward, as we saw in the previous section. For single-turn evals, simply provide the test case parameters as dynamic variables in your evaluation prompt, and out you get a score.

However for multi-turn evals, you'll need a prompt that:
- Takes into account entire conversations
- Calculates a score based on portions of a conversation
- Consider any tool calling and retrieval context within turns
In fact, often times a conversation can get length and the best way to evaluate it is to partition it into several list of turns instead:

Despite how different single and mult-turn LLM-as-a-judge may look, they both actually fall under the single-output LLM-as-a-judge category. For pairwise comparison, we generally don't do it for multi-turn since that would overload the LLM judge with too much context, hence it doesn't work as well compared to single-turn pairwise comparisons.
Techniques and Algorithms for LLM Judge Scoring
LLM-as-a-judge, at least for the implementations shown in above sections, can suffer from several problems:
- Reliability – Scores may vary across runs due to randomness or prompt sensitivity.
- Bias – Judges can show position bias (favoring the first or last response), or favor outputs generated by the same model family as the judge itself.
- Verbosity preference – Judges often reward longer, more detailed answers even when they are less accurate or less useful.
- Accuracy – Judges may misinterpret the rubric, overlook factual mistakes, or hallucinate justifications for a score.
These limitations means we need better techniques and algorithms, as is implemented in Confident AI.
G-Eval
G-Eval is a SOTA, research-backed framework that uses single-output LLM-as-a-judge to evaluate LLM outputs on any custom criteria using everyday language. It's evaluation algorithm is as follows:
- Generate a series of CoTs (chain of thoughts) based on an initial criteria
- Use these CoTs as evaluation steps in your evaluation prompt
- Dynamically include test case arguments in the evaluation prompt as well
G-eval was first introduced in the paper “NLG Evaluation using GPT-4 with Better Human Alignment”:
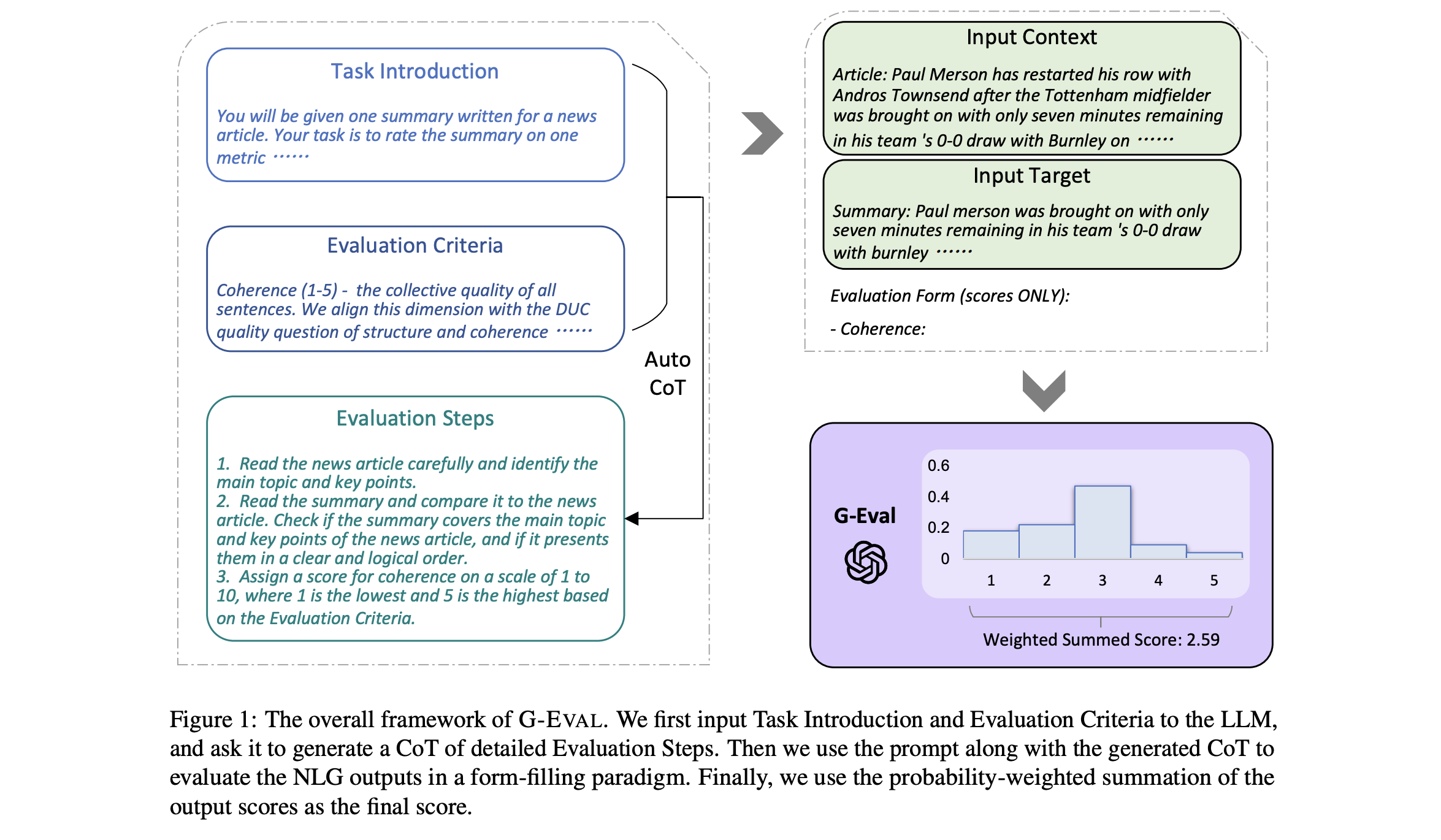
G-Eval makes great LLM evaluation metrics for subjective criteria because it is accurate, easily tunable, and surprisingly consistent across runs. Here's how you would use it in deepeval for running local evals:
from deepeval.metrics import GEval
from deepeval.test_case import LLMTestCaseParams
correctness_metric = GEval(
name="Correctness",
criteria="Determine whether the actual output is factually correct based on the expected output.",
evaluation_params=[LLMTestCaseParams.ACTUAL_OUTPUT, LLMTestCaseParams.EXPECTED_OUTPUT],
)In fact, all custom metrics you create on the platform is also powered by G-Eval. Confident AI now supports both single and multi-turn G-Eval:
from deepeval.test_case import ConversationalTestCase
from deepeval.metrics import ConversationalGEval
metric = ConversationalGEval(
name="Professionalism",
criteria="Determine whether the assistant has acted professionally based on the content."
)More information on G-Eval can be found here.
DAG
Deep Acyclic Graph (DAG) is a decision-tree based, deterministic, single-output LLM-as-a-judge metric. Each node in the DAG is a verdict, while each node contains the logic for which the LLM judge has to work through. In the end, the leaf nodes will return the score and reason.
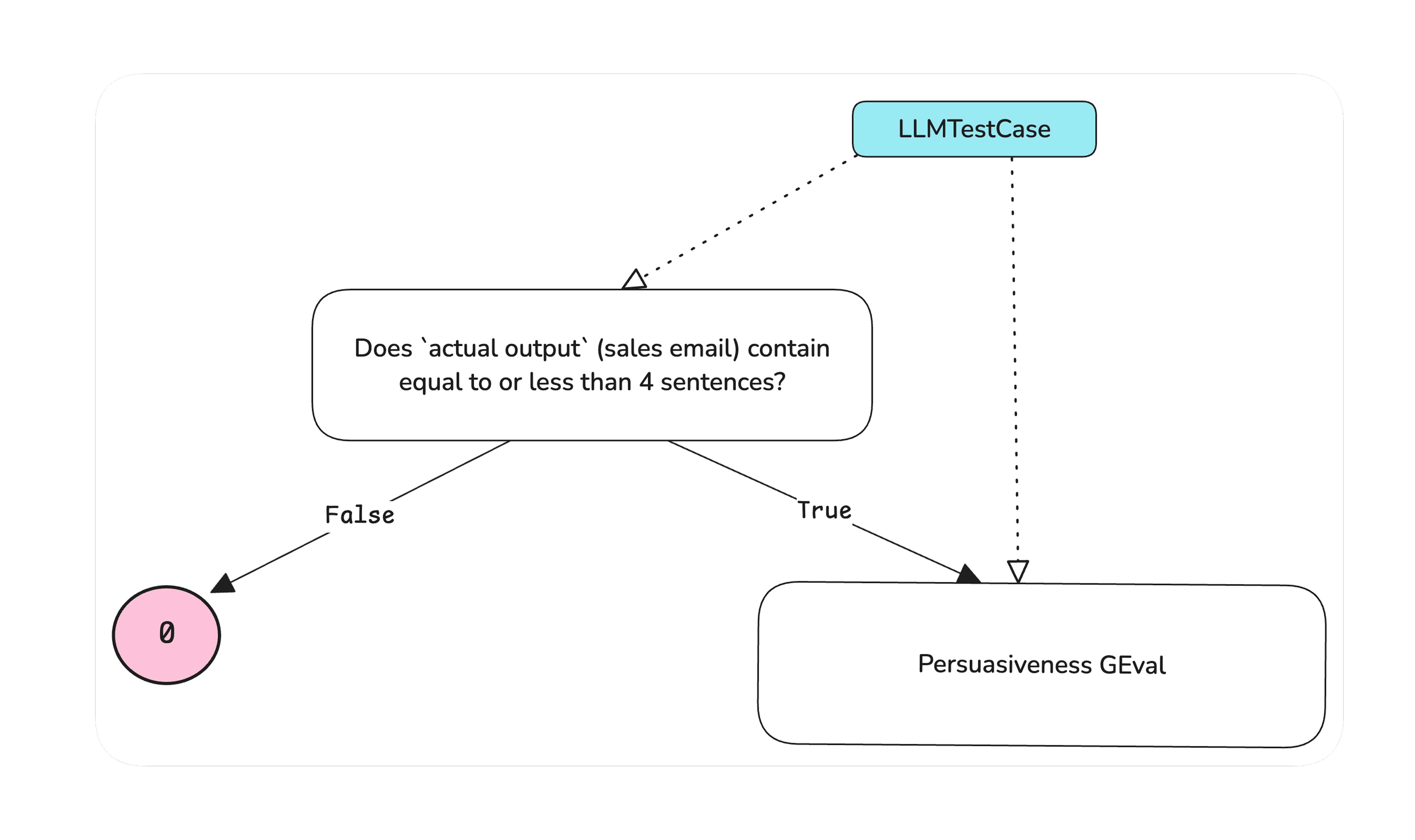
The DAG metric is currently not yet available on the platform, but you can run it through deepeval for local evals:
from deepeval.test_case import LLMTestCase, LLMTestCaseParams
from deepeval.metrics.dag import (
DeepAcyclicGraph,
TaskNode,
BinaryJudgementNode,
NonBinaryJudgementNode,
VerdictNode,
)
from deepeval.metrics import DAGMetric, GEval
geval_metric = GEval(
name="Persuasiveness",
criteria="Determine how persuasive the `actual output` is to getting a user booking in a call.",
evaluation_params=[LLMTestCaseParams.ACTUAL_OUTPUT],
)
conciseness_node = BinaryJudgementNode(
criteria="Does the actual output contain less than or equal to 4 sentences?",
children=[
VerdictNode(verdict=False, score=0),
VerdictNode(verdict=True, child=geval_metric),
],
)
# create the DAG
dag = DeepAcyclicGraph(root_nodes=[conciseness_node])
metric = DAGMetric(dag=dag)Notice that you can include G-Eval as the leaf node as well. This will allow you apply LLM-as-a-judge for more decision based filtering, while still allowing a subjective scoring at the end.
QAG
Question-answer-generation (QAG) is a single-output LLM-as-a-judge technique to compute LLM metric scores according to some sort of mathematical question. Instead of asking an LLM to come up with a score based on some criteria like G-Eval, QAG works by:
- Breaking test case arguments down into more fine grained "units"
- Applying LLM-as-a-judge to each fine grained "unit'
- Aggregate the verdicts of each LLM judge to compute a score and reason
Here's a tangible example with the answer relevancy metric:
- Break the actual output down into "statements", which is defined as coherent groups of text (e.g., sentences, paragraphs, etc.)
- For each statement, determine whether it is relevant to the input
- The final score is the proportion of relevant statements found in the actual output
On Confident AI, this is all handled by deepeval:
from deepeval.test_case import LLMTestCase
from deepeval.metrics import AnswerRelevancyMetric
test_case = LLMTestCase(input="...", actual_output="...")
metric = AnswerRelevancyMetric()
metric.measure(test_case)
print(metric.score, metric.reason) # QAG score reason hereThe reason why it is called QAG, is because this technique leverages closed-ended questions to confine LLM outputs to something that can be aggregated. In this example, instead of asking the LLM judge to do everything in a one-shot fashion, our algorithm only allowed the LLM judge to output a "yes" or "no" as verdicts to whether each statement is relevant. This makes it possible to confine a score to a mathematical formula.
LLM arena
LLM arena is traditionally an elo voting system to select the best performing LLM, but in this case we are applying pairwise LLM-as-a-judge to automate the voting process.
In Confident AI, this is done using the ArenaGEval metric, and only supports single-output:
from deepeval.test_case import ArenaTestCase, LLMTestCase, LLMTestCaseParams
from deepeval.metrics import ArenaGEval
a_test_case = ArenaTestCase(
contestants={
"GPT-4": LLMTestCase(
input="What is the capital of France?",
actual_output="Paris",
),
"Claude-4": LLMTestCase(
input="What is the capital of France?",
actual_output="Paris is the capital of France.",
),
},
)
metric = ArenaGEval(
name="Friendly",
criteria="Choose the winner of the more friendly contestant based on the input and actual output",
evaluation_params=[
LLMTestCaseParams.INPUT,
LLMTestCaseParams.ACTUAL_OUTPUT,
],
)
The ArenaGEval metric is currently only available for local evals in development (same as DAG).
Using LLM Judges for Metrics
If LLM judges are the core evaluation engine, metrics are the scaffolding around it. A metric determines the:
- Evaluation criteria/rubric
- Evaluation algorithm
- Passing threshold
- Which test case parameters should be used
In Confident AI, we generally won't refer to LLM-as-a-judge directly going forward, because metrics encapsulates more information about how evals should be ran.
Application-Based Metrics
Every LLM use case that you're building should have 1-3 application-based metrics. These metrics are based entirely on the way your LLM app is built and is use case agnostic.
RAG
In a RAG context, there are 5 single-turn metrics that evaluates the retriever and generator as separate components:
- Answer Relevancy: Measures how relevant the LLM’s response is to the user’s query
- Faithfulness: Evaluates whether the LLM’s response is supported by the retrieved context
- Contextual Relevancy: Assesses how relevant the retrieved context is to the query
- Contextual Recall: Measures the precision of the retrieved context
- Contextual Precision: Evaluates the recall of the retrieved context
Agents
For agents, there are 3 main single-turn metics centered around task completion and tool calling:
- Task Completion: Evaluates whether the agent successfully completed the assigned task
- Tool Correctness: Measures whether the agent used the correct tools for a given task
- Arugment Correctness: Measures whether the agent passed in the correct arguments for a given tool call
The task completion metirc is an extremely unique one that evalutes not on test cases, but on entire traces.
Chatbots
For chatbots, these will be multi-turn metrics:
- Turn Relevancy: Evaluates how relevant each response is to the ongoing conversation
- Turn Faithfulness: Evaluates how relevant each response is to the ongoing conversation
- Conversation Completeness: Measures whether the conversation addresses all aspects of the user’s request
- Role Adherence: Evaluates how well the LLM adheres to its assigned role
- Knowledge Retention: Measures how well the LLM retains information across conversation turns
You'll notice Confident AI's multi-turn metrics also takes RAG into account.
Use Case-Specific Metrics
Use case specific metrics, in contrary to the previous section, are application agnostic. and we recommend having 1-2 custom metrics in your evaluation suite.
You'll need to create custom metrics for use case specific metrics:
- G-Eval: A general-purpose evaluation metric for LLM outputs
- DAG: A decision-tree based LLM-evaluated metric
- Conversational G-Eval: A multi-turn general-purpose evaluation metric for LLM conversations
Currently, only G-Eval is supported on Confident AI platform. However, you can still leverage DAG in development by creating it locally.
Create Custom Metrics
You can create metrics either locally or remotely on the platform.
Local Evals
- Run evaluations locally using
deepevalwith full control over metrics - Support for custom metrics, DAG, and advanced evaluation algorithms
Suitable for: Python users, development, and pre-deployment workflows
Remote Evals
- Run evaluations on Confident AI platform with pre-built metrics
- Integrated with monitoring, datasets, and team collaboration features
Suitable for: Non-python users, online + offline evals for tracing in prod
You can learn everything about creating custom metrics here.
Next Steps
You now have everything you need to know to start running evaluations. Choose which best suits you to begin: