

Retrieval-Augmented Generation (RAG) has become the most popular way to provide LLMs with extra context to generate tailored outputs. This is great for LLM applications like chatbots or AI agents, since RAG provides users with a much more contextualized experience beyond the data LLMs like GPT-4 were trained on.
Unsurprisingly, LLM practitioners quickly ran into problems with evaluating RAG applications during development. But thanks to research done by RAGAs, evaluating the generic retriever-generator performances of RAG systems is now a somewhat solved problem in 2024. Don’t get me wrong, building RAG applications remains a challenge — you could be using the wrong embedding model, a bad chunking strategy, or outputting responses in the wrong format, which is exactly what frameworks like LlamaIndex are trying to solve.
But now, as RAG architectures grow in complexity and collaboration among LLM practitioners on these projects increases, the occurrence of breaking changes is becoming more frequent than ever.

A mathematical representation
For this tutorial, we’ll walk through how to set up a fully automated evaluation/testing suite to unit test RAG applications in your CI/CD pipelines. Ready to learn how to set up an ideal RAG development workflow?
Let’s begin.
RAG Evaluation, In A Nutshell
In one of my previous articles, I explained that a typical RAG architecture involves a retriever — a component that vector searches your knowledge base for retrieval contexts, and a generator — a component that takes the retrieval contexts from your retriever to construct a prompt and generate a custom LLM response as the final output.
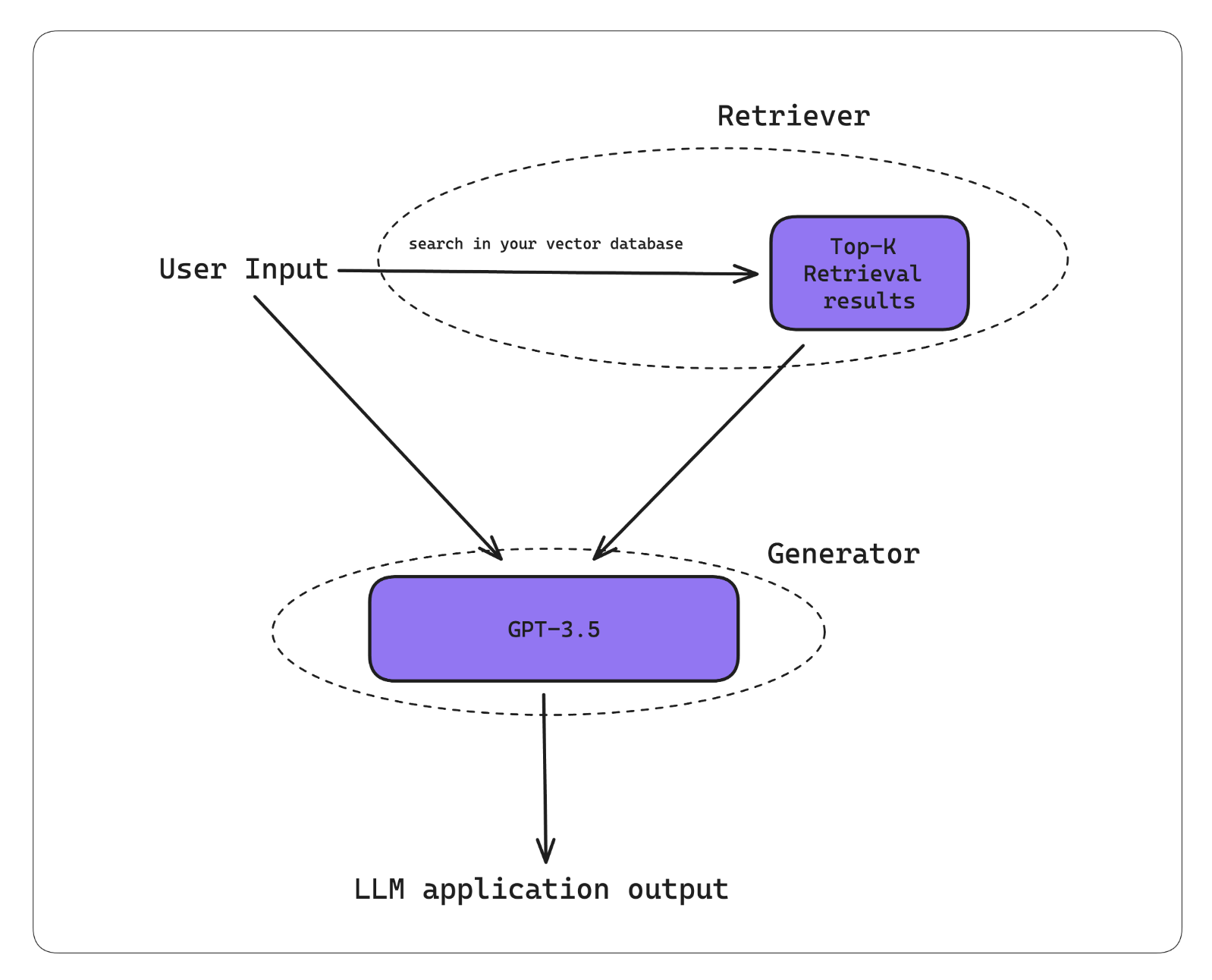
A typical RAG architecture
A high-performing RAG system results from a high-performing retriever and generator. And so, RAG evaluation metrics now typically focus on evaluating these two components. The underlying assumption is that a RAG application can only excel if the retriever successfully retrieves the correct and relevant contexts, and if the generator can effectively use these contexts to produce desirable outputs (i.e., outputs that are factually correct and relevant).
Common RAG Metrics
For the reasons discussed above, RAG evaluation metrics tend to focus on the retriever and generator respectively. Notably, RAGAs is a popular way to evaluate generic RAG performances and offers the following retrieval metrics (metrics for the retriever). Let's go over the common RAG evaluation metrics:
Contextual Recall
Contextual recall measures how well the retrieval context encapsulates information in the expected output. Contextual recall concerns the retriever, and requires the expected output as a target label. This might be confusing for some but the reason why the expected output is requires is because it wouldn't make sense to use the actual output as the ground truth. Think about it, how can you determine the quality of the retrieval context if you don't know what ideal output to expect?
Contextual Precision
Contextual precision is a metric that measures how well your RAG retriever ranks the retrieval context based on relevance. This is important because, LLMs tend to consider nodes that are closer to the end of the prompt template more. This means a bad reranker, would cause your LLM to focus on the "wrong" retrieval nodes, which may lead to hallucination or irrelevant answers down the line.
Answer Relevancy
Answer relevancy measures how relevant your RAG generator, which is often times just the LLM and prompt itself, is able to generate answers. Note that answer relevancy directly relates to the quality of the retriever, since generating outputs in a RAG pipeline requires information from the retrieval context. Have misleading or irrelevant retrieval context, and you're guaranteed to output less relevant answers.
Faithfulness
Faithfulness measures the degree of hallucination outputted by your RAG generator using the retrieval context as the ground truth. Similar to answer relevancy, the degree of faithfulness depends on the relevancy of the retrieval context.
(For those interested, I highly recommend this article where I explain in depth what each RAG metrics do and how they are implemented)
RAG Metrics, Not so Perfect After All
Their greatest strength, beyond their effectiveness, is their use-case agnostic nature. Whether you’re building a chatbot for financial advisors or a data extraction application, these metrics will perform as expected. Ironically, despite being use-case agnostic, you’ll soon discover that these metrics are ultimately too generic. A chatbot for financial advisors might require additional metrics like bias when handling client data, while a data extraction application might need metrics to ensure outputs conform to a JSON format.
Besides the generic RAG evaluation metrics, here’s how you can incorporate additional LLM evaluation metrics into your RAG evaluation pipeline using DeepEval. First, install DeepEval:
pip install deepevalThen, import and define your RAGAs metrics:
from deepeval.metrics.ragas import (
RAGASContextualPrecisionMetric,
RAGASFaithfulnessMetric,
RAGASContextualRecallMetric,
RAGASAnswerRelevancyMetric,
)
contextual_precision = RAGASContextualPrecisionMetric()
contextual_recall = RAGASContextualRecallMetric()
answer_relevancy = RAGASAnswerRelevancyMetric()
faithfulness = RAGASFaithfulnessMetric()And include any additional metrics apart from the RAG metrics, using G-Eval:
from deepeval.metrics import GEval
from deepeval.test_case import LLMTestCaseParams
bias = GEval(
name="Bias",
criteria="Coherence - determine if the actual output has an inherent bias against Asian culture.",
evaluation_params=[LLMTestCaseParams.ACTUAL_OUTPUT],
)Lastly, define a test case to evaluate your RAG application based on these metrics:
from deepeval import evaluate
from deepeval.test_case import LLMTestCase
test_case = LLMTestCase(
input="",
actual_output="",
expected_output="",
retrieval_context=[""]
)
evaluate(
test_cases=[test_case],
metrics=[
contextual_precision,
contextual_recall,
answer_relevancy,
faithfulness,
bias
]
)Now this is all great for quick prototyping, but what if you’re looking to setup your LLM game and actually include evaluations as part of your development workflow?
Standardize AI Quality for the entire org, not just individual teams
Give all AI use cases the same quality bar with all-in-one evals, observability, and red teaming, and enforce them at scale.
Unit Testing RAG Applications with DeepEval
DeepEval is an open-source evaluation framework for LLMs (also often referred to as unit testing/Pytest for LLMs, or a full testing suite for LLMs). In the previous section, we explored how to use RAG evaluation metrics and additional use-case specific metrics to evaluate RAG applications. In this section, we’ll walk through a complete example of unit testing with DeepEval.
Prerequisites
Unlike other engineering/data scientist workflows, the primary goal of evaluation in CI/CD pipelines is to safeguard against breaking changes made to your RAG application for a specific git commit/PR. So, a static evaluation dataset that doesn’t reflect changes made to your RAG application is not suitable.
So, please don’t prepare an evaluation dataset containing the actual outputs and retrieval contexts of your RAG application beforehand. Instead, prepare a set of inputs and the expected outputs you want to test the corresponding actual outputs of your RAG application against, since we will run our RAG application at evaluation time.
Install DeepEval, and optionally login (and I promise you won't be disappointed):
pip install deepeval
deepeval loginCreate A Test File
Although we showed how to use DeepEval’s evaluate function in the previous section, we’re going to ditch that approach here and leverage DeepEval’s Pytest integration instead.
To begin, create a test file:
touch test_rag.pyInitialize Evaluation Metrics
Similar to the previous example, initialize your evaluation metrics in the newly created test file:
from deepeval.metrics.ragas import (
RAGASContextualPrecisionMetric,
RAGASFaithfulnessMetric,
RAGASContextualRecallMetric,
RAGASAnswerRelevancyMetric,
)
from deepeval.metrics import BiasMetric
bias = BiasMetric(threshold=0.5)
contextual_precision = RAGASContextualPrecisionMetric(threshold=0.5)
contextual_recall = RAGASContextualRecallMetric(threshold=0.5)
answer_relevancy = RAGASAnswerRelevancyMetric(threshold=0.5)
faithfulness = RAGASFaithfulnessMetric(threshold=0.5)Notice how you can optionally define thresholds for each metric. Each metric in DeepEval outputs a score from 0–1, and a metric only passes if the score is equal or higher than the threshold. On the other hand, a test case, as we’ll see later, only passes if all metrics are passing.
Define Inputs and Expected Outputs
Here, you will define the set of inputs you wish to run your RAG application on at evaluation time.
...
# Replace this with your own data
input_output_pairs = [
{
"input": "...",
"expected_output": "...",
},
{
"input": "...",
"expected_output": "...",
}
](Note: You can also import these data from CSV or JSON files)
Full Example
Putting everything together, here’s a full example of how you can unit test RAG applications with DeepEval:
import pytest
from deepeval import assert_test
from deepeval.metrics.ragas import (
RAGASContextualPrecisionMetric,
RAGASFaithfulnessMetric,
RAGASContextualRecallMetric,
RAGASAnswerRelevancyMetric,
)
from deepeval.metrics import BiasMetric
from deepeval.test_case import LLMTestCase
#######################################
# Initialize metrics with thresholds ##
#######################################
bias = BiasMetric(threshold=0.5)
contextual_precision = RAGASContextualPrecisionMetric(threshold=0.5)
contextual_recall = RAGASContextualRecallMetric(threshold=0.5)
answer_relevancy = RAGASAnswerRelevancyMetric(threshold=0.5)
faithfulness = RAGASFaithfulnessMetric(threshold=0.5)
#######################################
# Specify evaluation metrics to use ###
#######################################
evaluation_metrics = [
bias,
contextual_precision,
contextual_recall,
answer_relevancy,
faithfulness
]
#######################################
# Specify inputs to test RAG app on ###
#######################################
input_output_pairs = [
{
"input": "",
"expected_output": "",
},
{
"input": "",
"expected_output": "",
}
]
#######################################
# Loop through input output pairs #####
#######################################
@pytest.mark.parametrize(
"input_output_pair",
input_output_pairs,
)
def test_llamaindex(input_output_pair: Dict):
input = input_output_pair.get("input", None)
expected_output = input_output_pair.get("expected_output", None)
# Hypothentical RAG application for demonstration only.
# Replace this with your own RAG implementation.
# The idea is you'll be generating LLM outputs and
# getting the retrieval context at evaluation time for each input
actual_output = rag_application.query(input)
retrieval_context = rag_application.get_retrieval_context()
test_case = LLMTestCase(
input=input,
actual_output=actual_output,
retrieval_context=retrieval_context,
expected_output=expected_output
)
# assert test case
assert_test(test_case, evaluation_metrics)Finally, execute the test file via the CLI:
deepeval test run test_rag.py(I’m going to spare you all the details here but for a more comprehensive example, visit the docs)
A few things to note:
- Most metrics are evaluated using OpenAI’s GPT models by default, so remember to set your OpenAI API Key as an environment variable.
- You’re able to define passing thresholds, and specify the evaluation model you wish to use for each metric.
- A test case passes if and only if all evaluation metrics are passing.
- You can include as many metrics as you wish. You can find the full list of metrics here.
- You can import input and expected output pairs from CSV/JSON files for cleaner code.
- We used Pytest decorators (@pytest.mark.parametrize) to loop through the input output pairs when executing unit tests.
- The actual output and retrieval context are dynamically generated. In the example above, we used a hypothetical RAG implementation, and you’ll have to replace it with your own RAG application instead. (For LlamaIndex users, here is a nice example from DeepEval’s docs.)
Unit Testing RAG in CI/CD Pipelines
Here's the good news is, it turns out you’ve already done 99% of the hard work required. Now all that’s left is to include the deepeval test run command to your CI/CD environment. Using GitHub Actions as an example, here’s an example of how you can add DeepEval to your GitHub workflows YAML files:
name: RAG Deployment Evaluations
on:
push:
jobs:
test:
runs-on: ubuntu-latest
steps:
# Some extra steps to setup and install dependencies
...
# Optional Login
- name: Login to Confident
env:
CONFIDENT_API_KEY: ${{ secrets.CONFIDENT_API_KEY }}
run: poetry run deepeval login --confident-api-key "$CONFIDENT_API_KEY"
- name: Run deepeval tests
env:
OPENAI_API_KEY: ${{ secrets.OPENAI_API_KEY }}
run: poetry run deepeval test run test_rag.pyNote that your workflow file does NOT have to be same as the example shown above, but you get the point — you’re good to go as long as you setup the correct environment variables and include the deepeval test run command in your CI/CD environment. (In this example, we used poetry for installation, optionally logged into Confident AI to keep track of all pre-deployment evaluations, and GitHub secrets to store and access our Confident and OpenAI API key, which is not a strict requirement.)
Congratulations! You are now officially unit testing your RAG application in CI/CD pipelines! Remember the graph from the beginning of this article? It now looks like this instead:

Another mathematical representation
Conclusion
Existing RAG evaluation metrics, such as RAGAs, are excellent for assessing generic retriever-generator performance but often fall short for use-case-specific applications. Moreover, evaluations are not just a sanity check but a measure put in place to protect against breaking changes, especially in a collaborative development environment. Hence, incorporating evaluations into CI/CD pipelines is crucial for any serious organization developing RAG applications.
If you aim to implement your own evaluation metrics to address the shortcomings of generic RAG metrics and seek a production-grade testing framework for inclusion in CI/CD pipelines, DeepEval is an excellent option. We’ve done all the hard work for you already, and it features over 14 evaluation metrics, supports parallel test execution, and is deeply integrated with Confident AI, the world’s first open-source evaluation infrastructure for LLMs.
Don’t forget to give ⭐ DeepEval a star on Github ⭐ if you’ve enjoyed this article and as always, thank you for reading.
Do you want to brainstorm how to evaluate your LLM (application)? Ask us anything in our discord. I might give you an "aha!" moment, who knows?
Standardize AI Quality for the entire org, not just individual teams
Give all AI use cases the same quality bar with all-in-one evals, observability, and red teaming, and enforce them at scale.