

Automated evals are how AI teams scale AI quality, but not every quality decision should begin and end with a metric score. This is especially true for AI agents. A bad response might come from the final answer, the retrieved context, a tool call, a routing decision, a policy boundary, or a multi-turn breakdown.
LLM judge metrics can catch a lot of this, but they still need human judgment to define what good output looks like, check whether metric scores match human expectations, and keep evaluation datasets grounded in truth.
Human-in-the-loop workflows keep evals aligned with human expectations and make that process systematic. Instead of asking subject matter experts (SMEs), QA teams, or domain experts to inspect random outputs forever (not scalable), they let you route the right cases to the right reviewers, capture structured feedback, and turn that feedback into better evals to a point where reviewers are barely needed.
In this guide, I'll walk through the three human-in-the-loop workflows that matter most for AI agent evaluation: metric alignment, AI agent failure review, and evaluation dataset curation. We'll also cover how to manage these processes at scale and how Confident AI supports the entire loop end-to-end.
TL;DR
- There are three core human-in-the-loop workflows. Metric alignment, AI agent failure review, and evaluation dataset curation.
- Metric alignment fixes metrics that disagree with humans. Reviewers compare automated scores against human judgment, then tune criteria, thresholds, rubrics, or judge prompts.
- AI agent failure review finds what metrics missed. Reviewers surface failures your metrics never flagged — through auto-surfaced signals, cost and latency, user feedback, and random sampling — then diagnose them across traces, spans, threads, and test cases.
- Evaluation dataset curation keeps evals current. Humans label expected behavior and promote high-value cases into the dataset: known failures first, then new topics, long outputs, and edge cases worth protecting from regressions.
- Every useful review should improve evaluation. It should improve an existing metric, add a new metric, or add an important test case back to the evaluation dataset.
What Are Human-in-the-Loop Workflows?
Human-in-the-loop workflows for AI agent evaluation are processes where humans review an AI agent's outputs and metric scores, then use that judgment to improve the evaluation system.
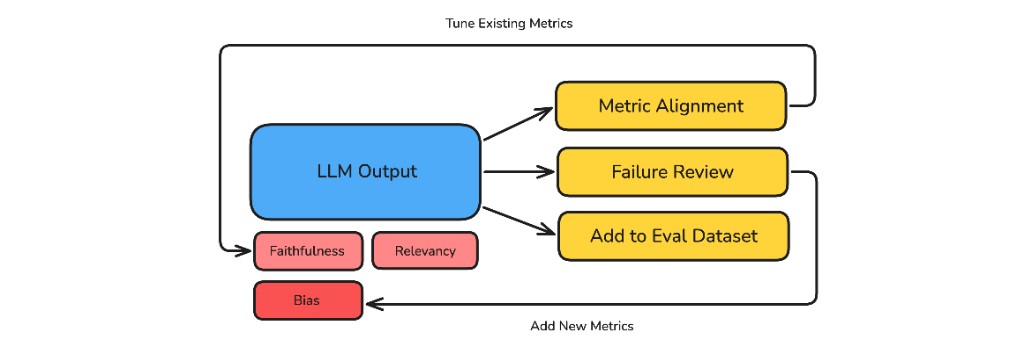
Human review of LLM outputs feeds metric alignment, failure review, and the evaluation dataset, which in turn tunes existing metrics and adds new ones.
This review happens across traces, spans, threads, and test cases, with feedback from an internal reviewer or directly from the end user. The end goal is to keep strengthening the evaluation system until it can reduce, and eventually replace, human review — so that quality scales with your evaluation system instead of with the size of your QA team, because adding reviewers does not scale and a maturing evaluation system does.
To get there, every review should result in one of three actionable items: improve an existing metric, add a new metric, or add a test case to the evaluation dataset.
Types of Human-in-the-Loop Workflows
Each of those three actions maps to a workflow type. Development and production are not separate workflows — each of the three runs in both, just on different data.
Workflow Type | What Humans Review | When to Review | What It Improves |
|---|---|---|---|
Metric alignment | Metric scores on LLM outputs, traces, spans, threads, and test cases | When automated scores exist to compare against human judgment | Metric accuracy, by tuning criteria, thresholds, rubrics, and judge prompts |
AI agent failure review | LLM outputs, traces, spans, threads, and test cases | On high-signal cases: thumbs-downs, tool errors, and escalations | Metric coverage, by adding missing metrics for uncovered failure modes and surfacing product bugs |
Evaluation dataset curation | LLM outputs, traces, spans, threads, and test cases | When a case should become durable coverage: production failures, new topics, and edge cases | CI/CD and benchmark evaluation dataset coverage |
Each of the three plays a distinct role in the same loop. Metric alignment keeps your existing metrics trustworthy by checking their scores against human judgment. AI agent failure review surfaces the failures those metrics miss, so the gaps become new coverage. Evaluation dataset curation promotes the cases worth remembering into a permanent dataset that future eval runs keep checking.
Human Annotation vs Human-in-the-Loop Workflow
Human annotation is the unit of feedback: a label, score, comment, expected output, or failure mode. A human-in-the-loop workflow is the operating loop that turns those annotations into more accurate metrics, broader coverage, and better evaluation datasets.
- Human annotation: a label, score, comment, expected output, failure mode, or structured form submission.
- Human-in-the-loop workflow: the loop that routes the right cases to humans, captures their judgment, and uses it to improve metrics, coverage, and datasets.
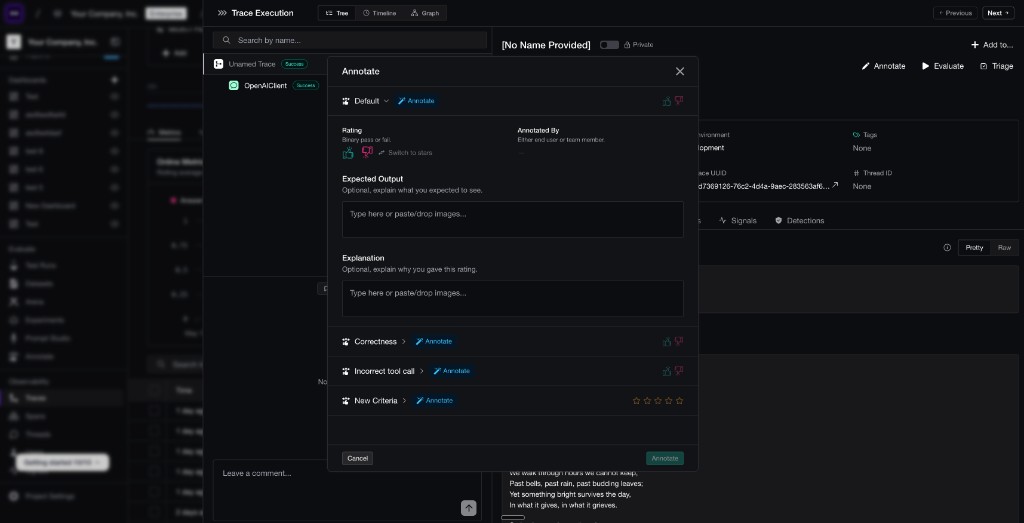
Annotating a trace on Confident AI: reviewers add a rating, expected output, explanation, and custom criteria such as correctness or an incorrect tool call.
What separates them is what happens next. If a reviewer marks 500 traces as "good" or "bad" and nothing downstream changes, you have annotation — useful as a record, but inert on its own.
If those same labels go on to tune metric criteria, reveal a missing metric, or seed new cases in your evaluation dataset, you have a human-in-the-loop workflow for AI agent evaluation: the same annotations, now wired into a loop that actually improves your evals.
Metric Alignment
Metric alignment is the human-in-the-loop workflow for measuring whether your metrics agree with human annotators. Every metric, and an LLM judge most of all, is only a proxy for the human you would otherwise put in the loop — so before you trust it to gate a release or score live traffic, you need to know how often it actually matches the people who understand the domain.
The goal itself is straightforward: if a domain expert says a response is bad, the metric that is supposed to catch that issue should fail it, and if the expert says it is good, the metric should pass it. Wherever the two diverge, you have found a metric that cannot yet be trusted on its own.
 Confident AI metric alignment shows how automated scores compare with human annotations.
Confident AI metric alignment shows how automated scores compare with human annotations.Humans review LLM judge scores against human expectations for metric alignment.
The process is the same in development and production; only what you review differs. In development, reviewers align metrics on test cases before release, comparing the expected output, metric score, and explanation against their own judgment. In production, they align metrics on real spans, traces, and threads that already have eval scores.
Development is the cheapest place to catch a misaligned metric, but most misalignments still surface in production, where new use cases, real user behavior, and edge cases you did not foresee expose gaps your test cases never covered.
Metric Alignment Annotations
Whether you're reviewing test cases or production traces, alignment comes down to one comparison: the human's judgment against the metric's score. What you are hunting for in that gap is false positives and false negatives — a metric may fail a good response because its criteria are too strict, or pass a bad response because its criteria are too vague.
Take a false negative. If a finance SME rejects an answer — say, the agent confidently cites a tax deduction limit that was repealed two years ago — and your "correctness" metric still passes it because the response reads fluent and well-structured, the metric is not a source of truth; it is a false sense of safety.
Which of the two is more dangerous depends on your use case. A false negative that lets a wrong answer through is costly in high-stakes domains like finance or health; a false positive that fails a good response is costly where it blocks shipping or buries reviewers in noise. Decide as a team which error your product can least afford, then tune your metrics to catch that one first.
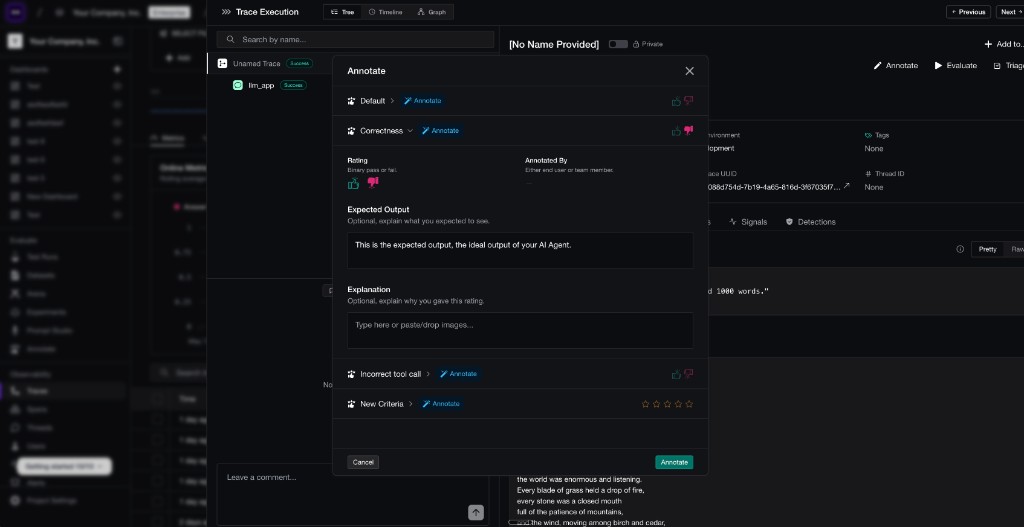
A metric annotation on Confident AI: a reviewer rates the Correctness metric with a binary pass/fail, adds the expected output, and explains the judgment.
For metric alignment, you can keep the annotation system simple. You are only checking whether the metric's score matches the human's judgment, and you already know what the metric is meant to measure — so it just needs to capture a verdict and the reason behind it:
- Human score or label (a binary thumbs up/down or star rating is enough); comparing it against the metric is what tells you whether the metric was right
- Reason for the judgment
- False positive or false negative label when it was wrong
- Suggested criteria, rubric, or threshold change
A good metric alignment workflow shows agreement rate, false positives, false negatives, and per-metric alignment. It should also show alignment by annotation or criterion, because that is how you find criteria that are too broad, too narrow, or unclear.
Using Annotations to Improve Metrics
Annotations only pay off when they can be used to improve the metric. Each disagreement your reviewers flagged — every false positive and false negative, along with the rationale behind it — is a concrete signal for what to fix.
When humans and metrics disagree, tune the metric criteria, examples, threshold, rubric, or judge prompt. How many of those levers you have depends on the metric: criteria, rubric, and few-shot examples are things you control only on a custom metric like G-Eval, while a prebuilt metric usually exposes just the threshold — past that, your move is to swap it or rebuild it as a custom metric.
Which lever to reach for depends on the failure: a metric that scores the wrong thing needs new criteria, while one that scores the right thing but draws the line in the wrong place only needs a different threshold. Start with the smallest change that closes the gap, then re-run the metric on the same annotated cases to confirm the disagreement is gone.
What to Tune | Tune It When |
|---|---|
Criteria | The metric judges the wrong thing, or its definition is too broad or too narrow |
Rubric | Scores are inconsistent because the scoring levels are not clearly defined |
Threshold | The judgment is right, but the pass/fail cutoff is too strict or too lenient |
Judge prompt or model | The judge misunderstands the task, format, or context it is scoring |
If the disagreement keeps repeating, decide whether the metric should be trusted for that use case at all. A metric that drifts from human judgment no matter how you tune it is not measuring what you think it is, and leaving it running only hides the problem behind a passing score.
This is especially important for LLM-as-a-judge metrics. A judge can sound confident while disagreeing with the people who actually understand the domain.
AI Agent Failure Review
AI agent failure review is the human-in-the-loop workflow for finding the failures your metrics never caught — the bad responses, broken agent behavior, and failure modes no metric marked as failed. Metric alignment assumes a metric was already watching the case; this workflow exists for everything no metric was watching at all.
That makes it broader than metric alignment. Reviewers are not just checking whether a score was right; they are diagnosing what actually happened, what should have happened instead, and whether the metric suite has a blind spot worth closing.
Surfacing AI Agent Failures in Production
Most of these failures show up in production, where real traffic produces behavior you could not anticipate. There, SMEs, QA teams, and domain experts should review outputs, traces, spans, and threads that carry evidence of a real issue.
Because these failures slip past your metrics, you surface them a few ways: auto-surfaced signals that route suspicious traces into review, non-judge signals like cost and latency (a run that is too slow or too expensive is a failure even when the output reads fine), user feedback such as thumbs-downs and escalations, and random sampling to catch whatever the rest miss.
The highest-signal cases usually come from:
Signal | Why It Deserves Review |
|---|---|
Thumbs-downs and escalations | Direct evidence the response did not help the user |
Tool errors, retrieval misses, retries | Agent-internal failures metrics miss |
High-latency or high-cost runs | Output may be fine, but too slow or costly for production |
New topics not yet in your dataset | Behavior outside current evaluation coverage |
Outputs that pass metrics but look wrong | A sign your metric suite is missing something |
Reviewing AI Agent Failures in Development
Cases in development are the easiest to catch, because you re-run the same benchmark on every change. In practice, that makes development review mostly about the test cases you just added — the rest of the suite has already been vetted — so it surfaces less new insight than production, where real traffic keeps producing failures you never thought to test for.
Failure Review Annotations
The annotation system is the same as the one for metric alignment — a score (a thumbs up/down or five-star rating), an explanation, and an expected output or outcome. What changes is the goal: in metric alignment the rationale helps you tune an existing metric, while here it helps you spot the metric you do not have yet, because reviewers are documenting new failure modes, not just grading known ones.
For serious teams with a robust set of evaluation criteria, there's one addition worth making. On top of that basic capture, you can build a form that defines what counts as a failure: a short questionnaire that asks a focused question per criterion — a multiple-choice question on how the agent performed, a yes/no on whether the user was satisfied, a free-text field for what went wrong — instead of a single pass/fail verdict.
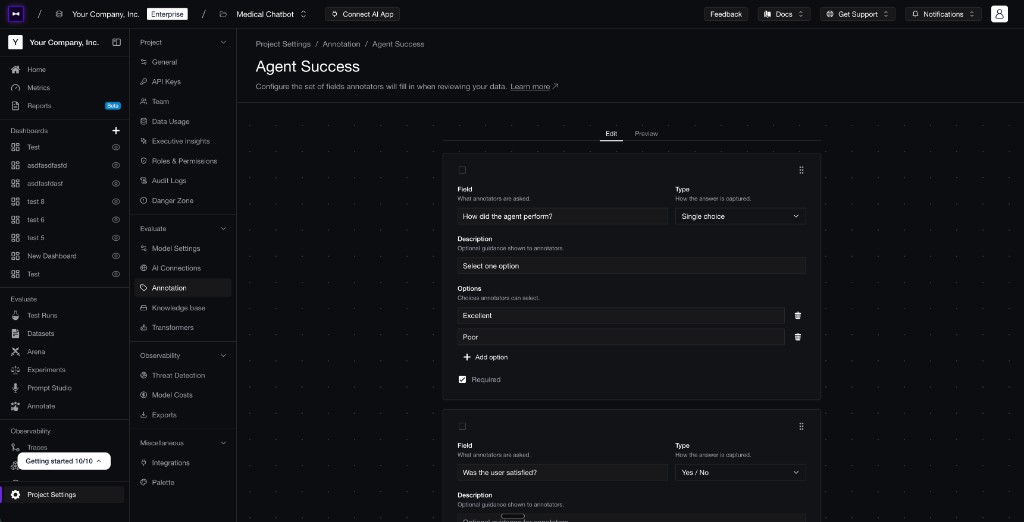
A failure-review form on Confident AI: reviewers answer one structured question per criterion, so recurring failures point straight to a missing metric.
This is worth the extra effort because a single verdict only tells you that a case is bad, not which part of it broke. Splitting the judgment into named criteria forces every reviewer to grade the same dimensions the same way, so their answers add up to a pattern instead of a pile of one-off comments. When the same criterion keeps failing across cases, that is your signal — each recurring failure is a candidate for a new metric, and the form is what makes it visible in the first place.
You can still sample randomly, but targeted review is usually higher leverage. Start with cases raised by user feedback, trace analysis, support escalations, or known issue signals.
End-User Feedback vs Internal Reviewer Feedback
End user feedback is part of human-in-the-loop evaluation, but it is not the same thing as internal review. It is usually a signal that something deserves a closer look, not the final diagnosis. Still, that signal is valuable: you won't be able to review everything yourself, and your users are often the best way to surface the failure cases you don't yet recognize. That makes their feedback extremely valuable.
End users can tell you whether an answer helped them. Internal reviewers can tell you why the system behaved the way it did and what should change: the metric criteria, the metric suite, or the evaluation dataset.
Entity | End User Feedback | Internal Reviewer Feedback | Why |
|---|---|---|---|
Final response or visible outcome | Yes | Yes | Users can judge whether the answer helped; reviewers can connect that outcome to system behavior |
Trace | Outcome only | Yes | Users experience the result; reviewers can inspect the full execution |
Span | Usually no | Yes | End users do not see internal retrieval, tool calls, model calls, or guardrails |
Thread | Yes | Yes | Users experience the whole conversation; reviewers can inspect turns and escalation logic |
Test case | No | Yes | Test cases are usually internal evaluation artifacts |
The two signals do different jobs: end-user ratings add a production signal, while internal reviews explain why the system failed.
So do not ask users to rate whether the retriever selected the right chunk — they cannot see it, and they should not have to. That kind of failure belongs to internal reviewers, who should inspect spans whenever the problem may live inside the system: wrong retrieval, bad tool arguments, unnecessary retries, weak guardrails, or planner mistakes.
Improving Metric Coverage With Error Analysis
AI agent failure review should improve metric coverage. If humans keep finding the same issue and no metric catches it, the fix is usually a new metric — not a tweak to an existing one, which is metric alignment's job.
This is where error analysis becomes useful. Reviewed failures should cluster into patterns, such as tool correctness, escalation quality, policy compliance, retrieval grounding, or multi-turn task completion. Each recurring cluster points to a metric worth adding.
 Confident AI error analysis clusters annotated failures into modes and recommended metrics.
Confident AI error analysis clusters annotated failures into modes and recommended metrics.Confident AI error analysis clusters human feedback into failure modes and recommends metrics.
Once you have failure modes, you can prioritize: add a new metric for the gap, add a test case to the evaluation dataset so the failure stays covered, or — when it is not an eval gap at all — file a product fix.
Many of those failures should not stop at a fix. A failed output a human confirms, or one a metric flags, is exactly the kind of case worth promoting into your evaluation dataset — which is the next workflow.
Evaluation Dataset Curation
Evaluation dataset curation is the human-in-the-loop workflow where human annotation becomes durable test coverage. Humans define what good behavior looks like, add new cases from production, and keep the dataset aligned with how users actually interact with your agent.
This asks a different question from metric alignment. Metric alignment asks whether a metric scored a case correctly. Curation asks something earlier: should this case be in the dataset at all, and what should its expected behavior be? The result is not a tuned metric. It is a growing library of cases your evaluation suite is measured against from then on.
Confident AI's dataset editor, where reviewers curate evaluation test cases and label the expected behavior for each one.
Adding to an Evaluation Dataset
The first question is simple — what belongs here? The lowest-hanging fruit is everything that already failed: cases where a metric failed, and the failures you confirmed during AI agent failure review. These are known problems, so locking them into the dataset keeps them from quietly regressing later.
A good dataset is not only failures, though. Add cases that currently pass but are still worth protecting: new topics, unusually long outputs, unexpected behaviors, and new use cases. Capturing them now prevents regressions when a prompt, model, or agent change breaks something that used to work.
These candidates come from both sides of the lifecycle. Production traffic constantly shows what the dataset is missing — pull from failed evals, user-reported issues, and support escalations, and when a trace exposes a real bug, add the input, context, expected behavior, metadata, and failure reason rather than just the verdict. Development adds the rest: new features, prompts, tools, and policy changes should become test cases before they turn into production incidents.
Labeling Expected Outputs
Adding a case is only half the job — each one needs a definition of what good looks like. For existing test cases, humans should label the expected output, expected tool call, or expected outcome. That label becomes the baseline for your metrics.
In many cases, no quality score is needed. If the task is to label the expected outcome, the output is the label itself.
This is where human feedback turns into evaluation infrastructure: humans identify the quality gap once, and every release afterward is checked against it automatically.
Managing Review at Scale
All three workflows are easy to run on a handful of cases; the hard part is operating them at production volume. Small teams can start with a few reviewers and a small queue, but once you have real traffic, human-in-the-loop evaluation needs one hub where SMEs, QA teams, support reviewers, and non-technical annotators can review traces, assign work, track progress, measure agreement rates, and complete structured annotations.
 Confident AI annotation queue for reviewing production traces and failures.
Confident AI annotation queue for reviewing production traces and failures.Confident AI annotation queues give teams one workspace to assign, queue, and track trace, span, thread, and test-case review at scale.
Assigning Reviewers
The first job at scale is matching cases to the people who can actually judge them: domain calls to SMEs, tool and retrieval failures to engineers, and visible-quality issues to QA or support reviewers. The wrong reviewer on the wrong case produces noise, not signal.
Whatever they decide should never sit in comments. Every completed review should flow into a metric update, a new metric, an evaluation-dataset case, or an issue ticket — without that path, human-in-the-loop evaluation decays into Slack threads, spreadsheets, screenshots, and forgotten trace IDs.
Automated Annotations
Automation can also make review faster without taking humans out of the loop. The highest-leverage helpers draft annotations for reviewers to approve or edit (a suggested rating, explanation, and expected output), route matching production traces into queues automatically, and cluster completed reviews into failure modes after the fact.
The human is still in the loop. The workflow is faster because automation prepares the review context and removes the busywork of starting from scratch without replacing human judgment.
Why Confident AI Is Best for Human-in-the-Loop Evaluation
The hard part of human-in-the-loop evaluation is not collecting labels. It is making sure those labels improve metrics, widen coverage, and strengthen evaluation datasets.
Confident AI is built for that full loop. You review test cases before release and ingest production traces, spans, and threads through Observatory, where signals auto-surface the cases worth a look — new topics, failing runs, and emerging failure modes no metric was watching for. You then route those into annotation queues, manually or with automations that match incoming traffic and assign each case to the right reviewer: domain calls to SMEs, tool and retrieval failures to engineers, visible-quality issues to QA. Reviewers complete structured annotations (a rating, explanation, and expected output or outcome), and Auto-Annotate can pre-fill those fields so they refine a suggestion instead of filling everything in by hand.
The bigger advantage is what happens after review. Confident AI connects those annotations to eval alignment, error analysis, and evaluation datasets. Alignment shows where metrics disagree with human labels, broken down by false positives, false negatives, and per-metric agreement. Error analysis clusters reviewed failures into failure modes and recommends new metrics. And any reviewed case can be added to a dataset so the same failure is caught on future runs.
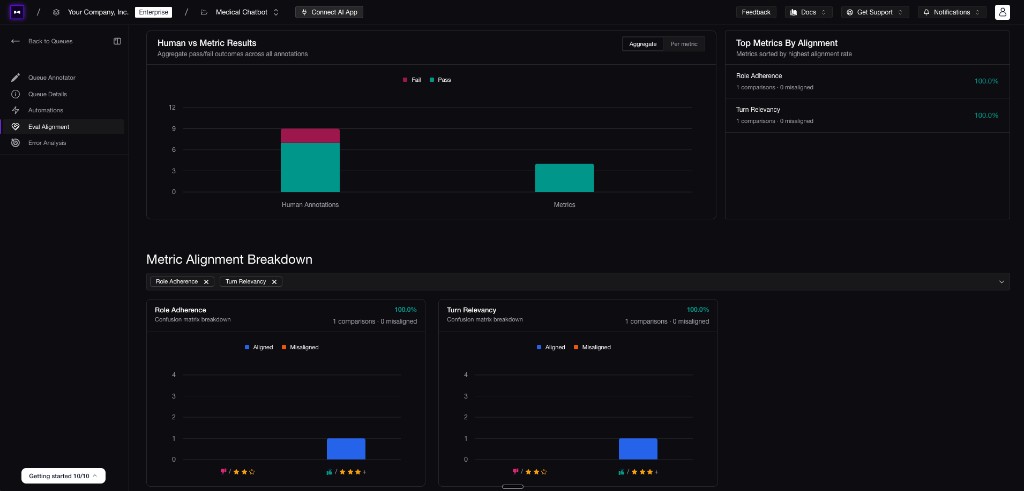
Confident AI's eval alignment compares human annotations against metric scores and breaks agreement down per metric, so you can see exactly where a metric disagrees with your reviewers.
That is why Confident AI is especially strong for AI agent evaluation. Agents fail across final responses, tool calls, retrieval steps, guardrails, memory, routing, and multi-turn behavior. Confident AI gives teams one workflow for reviewing those layers, aligning metrics with human judgment, and tying production behavior back to pre-release evals.
Common Pitfalls
Human-in-the-loop workflows fail in predictable ways, and almost all of them come down to feedback that never turns into a change.
Pitfall | The Fix |
|---|---|
Labels get collected but never used | Connect every annotation to a metric update, a new metric, or a dataset case |
Reviewers sample randomly and miss high-signal failures | Route the highest-signal cases first, and use random sampling only as a backstop |
Only final outputs get scored | Review spans and tool calls too, so retrieval, tool, policy, and multi-turn failures are not missed |
Vague labels like "bad" | Name the failure mode and the metric gap, not just a verdict |
Five-star ratings without definitions | Define every score, or fall back to binary pass/fail |
End-user feedback mixed with internal diagnosis | Keep user signals and reviewer diagnosis in separate lanes |
Misaligned metrics keep running | Retune or retire a metric once humans prove it disagrees with them |
Confirmed failures never re-enter the dataset | Promote important failures into the evaluation dataset for regression coverage |
The through-line is the same: route the cases where human judgment has the highest leverage, and make every review improve an existing metric, add a new metric, or add a test case to the evaluation dataset.
Conclusion
Human-in-the-loop workflows for AI agent evaluation are not about keeping humans in every decision forever. They use human judgment where automated evaluation needs context, so your metrics and evaluation datasets stay trustworthy as your agent keeps changing.
The loop is simple: label the data that defines good behavior, score it with metrics, and use production observability to surface the cases worth reviewing. Then compare human judgment against those scores, refine existing metrics, add missing ones, and feed the most important failures back into the evaluation dataset.
Do that consistently and your evals stop being a static checklist. They become a living evaluation loop that stays aligned as your product, users, prompts, models, and agents change.
Thanks for reading. When you are ready to build this workflow on your own AI app, get started with Confident AI for free.
Frequently Asked Questions
What are human-in-the-loop workflows for AI agent evaluation?
What is human-in-the-loop evaluation for AI agents?
What is the difference between human annotation and a human-in-the-loop workflow?
How do I set up a human annotation workflow for reviewing AI agent failures?
What should humans review in an AI agent evaluation workflow?
Should end users annotate traces, spans, or threads?
How does human-in-the-loop feedback improve LLM-as-a-judge metrics?
When should I route examples to human reviewers?
How many examples do I need for human-in-the-loop AI agent evaluation?
What is the best platform for human-in-the-loop AI agent evaluation?
How does Confident AI support human-in-the-loop evaluation?
What is the difference between annotation queues and error analysis?
Do you want to brainstorm how to evaluate your LLM (application)? Ask us anything in our discord. I might give you an "aha!" moment, who knows?
Standardize AI Quality for the entire org, not just individual teams
Give all AI use cases the same quality bar with all-in-one evals, observability, and red teaming, and enforce them at scale.