
Today we're launching AI Governance on Confident AI — the layer that turns the evals, observability, and red teaming your teams already run into one standard, enforced across every project (or AI use case) with a deploy gate. It's the feature nearly every team scaling AI eventually asks us for, and it's live now.
What is AI Governance?
Confident AI is already where your teams run evals, monitor production, and red team their AI. AI Governance is the layer on top: it takes those signals you're already producing — test runs, traces, alerts, risk assessments — and turns them into a standard you define once and apply everywhere.
Every AI use case assigned to a policy is held to the same bar, so "is this AI ready to ship?" has a real, evidence-backed answer instead of a gut call.
The Problem
When AI is one or two pilot projects, evaluation is whatever the team building it decides it should be. That's fine — until it isn't.
The moment you have a dozen AI applications across multiple teams, things fragment:
- No shared standard. Every team picks its own metrics, its own thresholds, and its own private definition of "good enough." Some teams run rigorous evals. Others ship on vibes.
- No enforcement. Even when standards exist on paper, nothing stops a team from skipping them. Eval suites live in a doc nobody reads and no pipeline checks.
- No proof. When your leadership, a customer, or your own team asks "how do you know this is safe and accurate?", the honest answer is a shrug and a Slack search.
The teams aren't careless — they just have no central place to define what "meeting the bar" means, and no mechanism to make sure it actually happens.
The Before vs. After
This pain lands hardest on the platform team — the people on the hook when leadership or a customer asks whether the company's AI is safe to ship.
Before: The platform team is a human governance layer — chasing a dozen product teams for eval scores before every launch, with no way to enforce the bar and no proof nothing regressed.
After: One standard, enforced. The platform team encodes it once as a policy, and the deploy gate blocks anything that doesn't meet it — automatically.
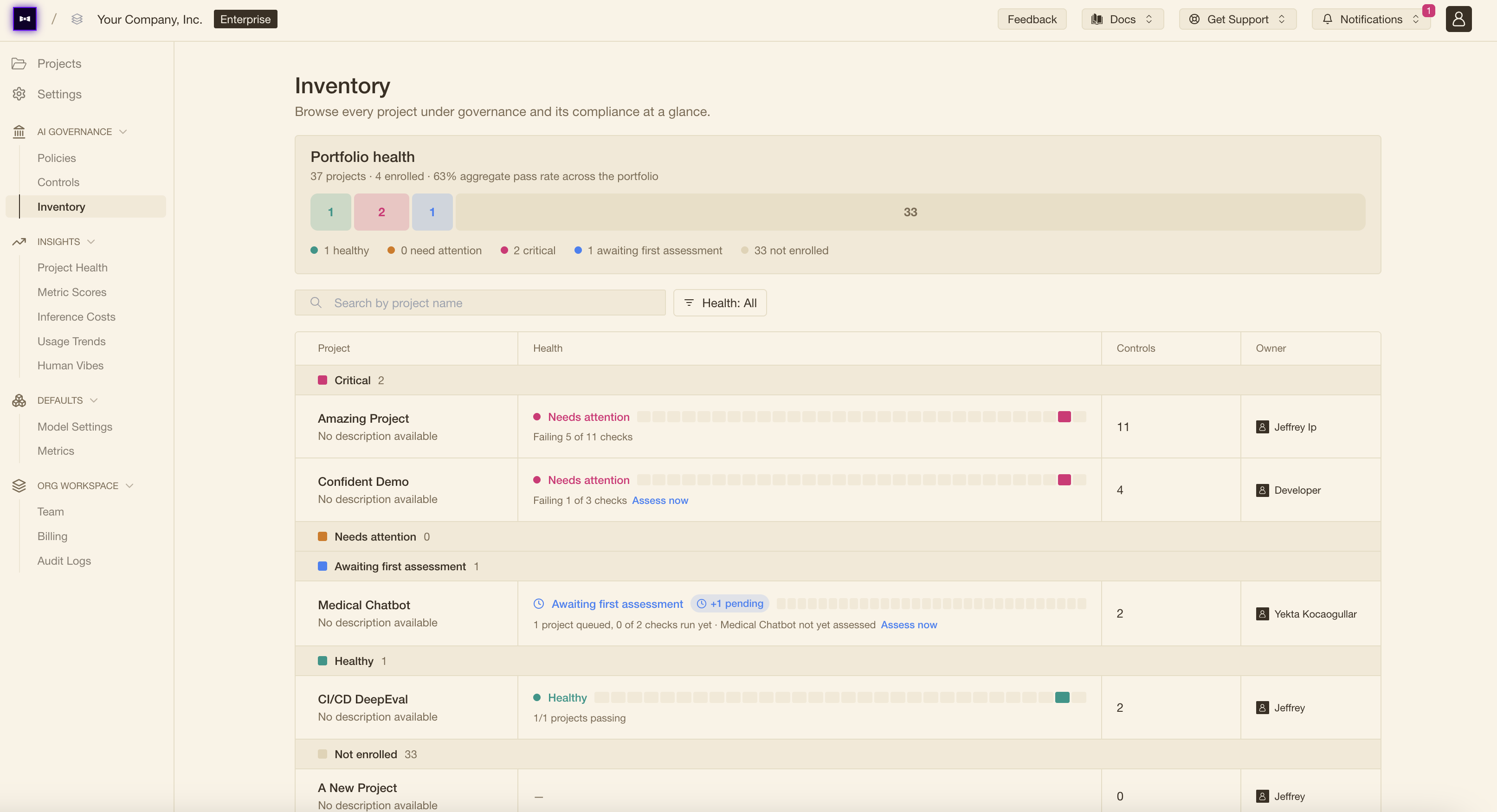
Policies: the standard you enforce
A policy is a named group of controls that represents a standard you set — for example, every use case must have tracing set up before it moves to production, or every POC must pass PII-leakage red teaming 100% of the time. A policy is met only when every control it contains passes; any FAIL, ERROR, or NO_DATA means it isn't.
Each AI use case belongs to at most one policy, and a single policy can govern many. Assign a policy and every use case under it is continuously assessed against the same set of controls — one bar, applied everywhere.
 Group controls into a policy and assign the AI use cases it governs on Confident AI.
Group controls into a policy and assign the AI use cases it governs on Confident AI.Controls: the requirements you measure
A control is a single, measurable requirement that's automatically assessed against the real state of an AI use case — its datasets, traces, alerts, test runs, risk assessments, and more. Controls come in four types, each covering a different slice of your AI lifecycle:
- Operational — static configuration checks, e.g. datasets exist, traces are being logged, alerts are configured.
- Runtime — threshold-based metrics over your observability data (traces, spans, threads), assessed over a trailing 24-hour window, the same model as alerts.
- Pre-deployment (evals) — gates on a recent evaluation test run, for example requiring the latest official run to pass.
- Pre-deployment (red teaming) — gates on a recent red teaming risk assessment before a release is allowed to ship.
Controls are also versioned — every configuration change appends a new version, so assessments always run against the latest while older versions stay on record.
Enforced continuously — and at deploy time
Governance isn't a report you run once a quarter. Each use case's controls are evaluated:
- On a daily schedule — every governed use case is reassessed automatically.
- On demand — re-run a policy's assessments anytime from the Governance page.
- As a deploy gate — block a release in CI/CD unless every control passes.
Wire the gate into your pipeline with the deepeval CLI (Python and TypeScript), or call the public API directly:
deepeval gateThe gate assesses every control in that use case's policy and exits with code 0 only when the policy is fully met — a non-zero exit stops your pipeline, preventing a release that doesn't meet your bar from ever shipping.
Why This Matters
There's a huge gap between "we run evals" and "our entire organization ships to the same bar." Most teams already have the raw signals — evals, observability, red teaming — on at least some of their apps. What's missing is the layer that turns those signals into a standard everyone is held to, and that stops the releases that fall short.
That's what governance is: the evidence layer on top of the work your teams already do on Confident AI. It makes "is this ready to ship?" answerable from data, not vibes.
Get Started
AI Governance is an enterprise feature on Confident AI.
- Read the AI Governance documentation to see policies, controls, and gating in full
- Contact us to enable it for your organization
And keep an eye on the blog this week — we've got more shipping.
Do you want to brainstorm how to evaluate your LLM (application)? Ask us anything in our discord. I might give you an "aha!" moment, who knows?
The Eval Platform for AI Quality & Observability
Confident AI is the leading platform to evaluate AI apps on the cloud, with metrics open-sourced through DeepEval.