
Welcome to Day 2 of Confident AI's Launch Week. Yesterday we launched Automated Error Analysis — today, we're tackling something that sounds simple but trips up almost every team I talk to.
Launch Week Day 2 (2/5): Scheduled Evals.
The Workflow Nobody Talks About
PMs and engineers run evaluations in CI/CD before deployment — that's table stakes. If you're not doing that, you've got bigger problems.
But there's another evaluation workflow that no one talks about: the one where stakeholders need evals run every X days so the team can sit together, review the results, find problems in their AI agents, and fix them before shipping.
It's the "recurring quality check" — the process that should be running in the background on a cadence, catching regressions and drift that a one-time CI/CD run will never surface.
Except... they forget. Every time.
The Problem
Here's what the typical workflow looks like today:
- Someone says "we should run evals regularly." Everyone agrees. Heads nod. A Slack reminder gets created.
- Week 1: evals run. Great. The team reviews the results, finds a few issues, fixes them.
- Week 2: someone's on PTO. The eval run slips. No one notices.
- Week 3: a sprint deadline hits. Evals get deprioritized. "We'll catch up next week."
- Week 6: a stakeholder asks "when did we last run evals?" Silence. Scrambling. Someone fires up a notebook, tries to remember which dataset to use, which metrics to run, and how the variable mappings were configured last time.
The result? Evals that were supposed to run weekly haven't run in a month. By the time someone finally reruns them, the model has drifted, the prompts have changed, and the team is debugging in a panic right before a release.
This isn't a discipline problem — it's a tooling problem. Manual processes that rely on humans remembering to do something on a schedule always fall apart. The solution isn't better reminders. It's automation.
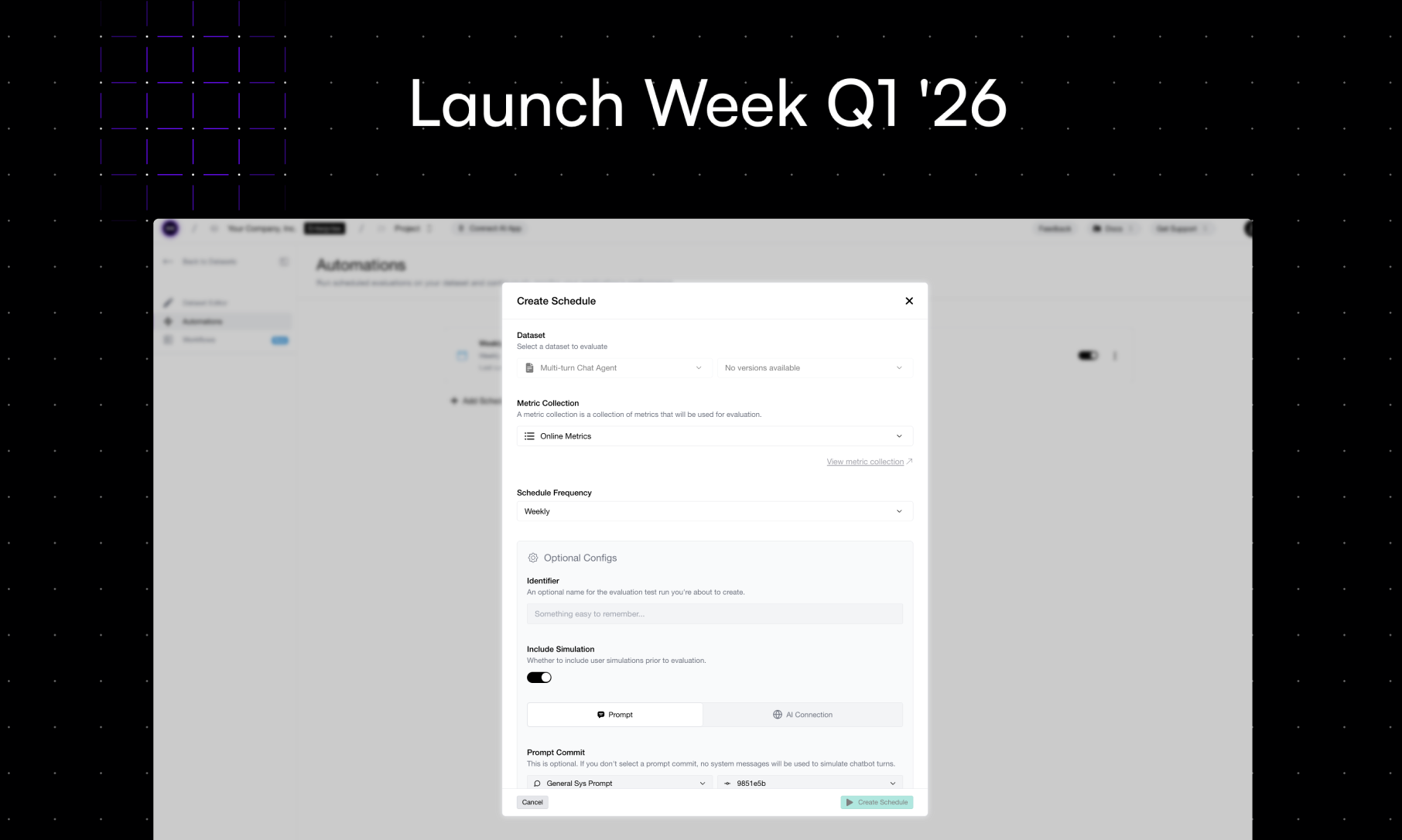
Scheduled Evals on Confident AI
Scheduled Evals is exactly what it sounds like — and it's dead simple:
- Set your eval frequency. Daily, weekly, biweekly — whatever cadence makes sense for your team.
- Configure variable mappings. Map your dataset columns to the variables your metrics expect. If you're working with multi-turn datasets, you can optionally configure simulation so Confident AI generates the conversations for you.
- Done.
That's it. Confident AI runs your evals on the schedule you set, with the dataset and metrics you configured. Results show up on the platform automatically — ready for your team to review without anyone having to remember to kick off a run.
No more "wait, when did we last run evals?" No more scrambling before a release. No more broken Slack reminders that everyone mutes after week two.
Why This Matters
CI/CD evals and scheduled evals serve fundamentally different purposes. CI/CD evals are gatekeepers — they block bad code from shipping. Scheduled evals are monitors — they catch slow drift, dataset staleness, and regression patterns that only show up over time.
Most teams only have the first one. The second one lives in someone's head as a good intention that never becomes a habit. Scheduled Evals turns that good intention into infrastructure.
And here's the thing — the teams that do run evals regularly are the ones that actually improve their LLM apps over time. They're the ones who catch that their answer relevancy dropped 8% over the last two weeks before it becomes a user-facing incident. They're the ones who walk into stakeholder reviews with data, not vibes.
What's Next
This is Day 2 of 5. Three more launches coming this week — and like yesterday, each one is about taking a workflow that teams know they should be doing and making it effortless on Confident AI.
Stay tuned — and if you want to set up Scheduled Evals for your team, sign up for Confident AI and start automating your eval cadence today.
Do you want to brainstorm how to evaluate your LLM (application)? Ask us anything in our discord. I might give you an "aha!" moment, who knows?
AI Quality for the entire organization, not just individual teams
Give all AI use cases the same quality bar with all-in-one evals, observability, and red teaming, and enforce them at scale.