
Let’s set the stage: I’m about to change my prompt template for the 44th time when I get a message from my manager: “Hey Jeff, I hope you’re doing well today. Have you seen the newly open-sourced Mistral model? I’d like you to try it out since I heard gives better results than the LLaMA-2 you’re using.”
Oh no, I think to myself, not again.
This frustrating interruption (and by this I mean the releasing of new models) is why I, as the creator of DeepEval, am here today to teach you how to build an LLM evaluation framework to systematically identify the best hyperparameters for your LLM systems.
Want to be one terminal command away from knowing whether you should be using the newly release Claude-3 Opus model, or which prompt template you should be using? Let’s begin.
What is an LLM Evaluation Framework?
An LLM evaluation framework is a software package that is designed to evaluate and test outputs of LLM systems on a range of different criteria. The performance of an LLM system (which can just be the LLM itself) on different criteria is quantified by LLM evaluation metrics, which uses different scoring methods such as LLM-as-a-judge depending on the task at hand. This process, is know as LLM system evaluation.
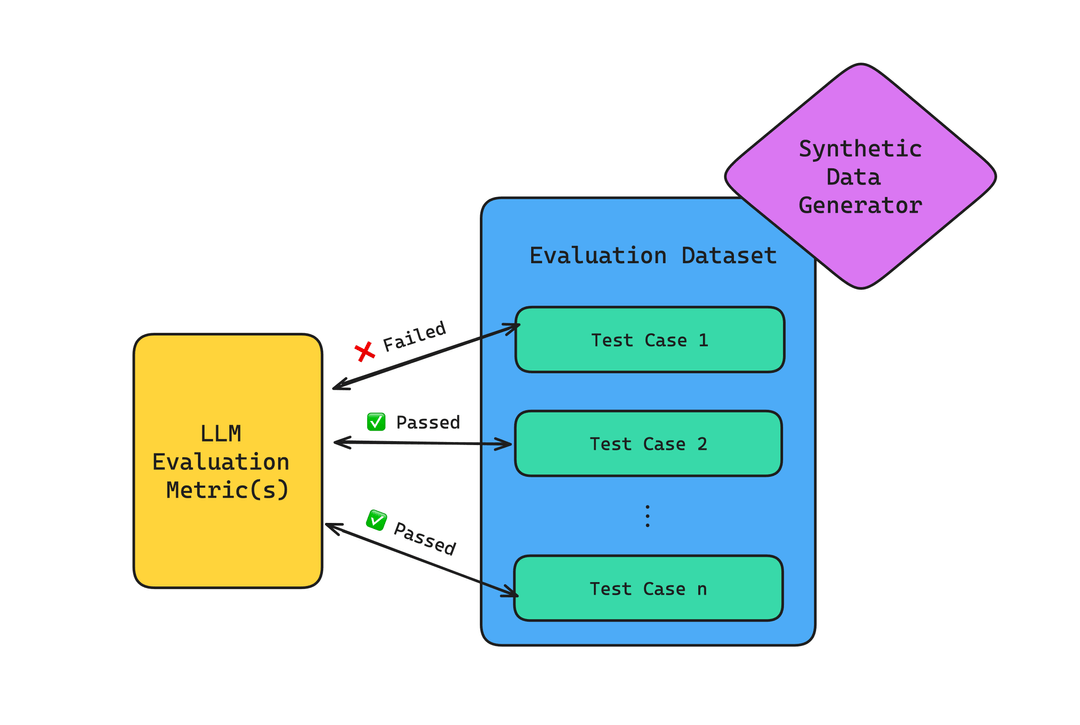
A typical LLM evaluation framework architecture
These evaluation metrics scores, will ultimately make up your evaluation results, which you can use to identify regressions (which some people call regression testing) in LLM systems over time, or even be used to compare LLM systems with one another.
For example, let's say I’m building a RAG-based, news article summarization chatbot for users to quickly skim through today’s morning news. My LLM evaluation framework would need to have:
- A list of LLM test cases (or an evaluation dataset), which is a set of LLM inputs-outputs pairs, the “evaluatee”.
- LLM evaluation metrics, to quantify my chatbot assessment criteria I hope it to perform well on, the “evaluator”.
For this particular example, two appropriate metrics could be the summarization and contextual relevancy metric. The summarization metric will measure whether the summaries are relevant and non-hallucinating, while the contextual relevancy metric will determine whether the my RAG pipeline’s retriever is able to retrieve relevant text chunks for the summary.
Once you have the test cases and necessary LLM evaluation metrics in place, you can easily quantify how different combinations of hyperparameters (such as models and prompt templates) in LLM systems affect your evaluation results.
Seems straightforward, right?
Challenges in Building an LLM Evaluation Framework
Building a robust LLM evaluation framework is tough, which is why it took me a bit more than 5 months to build DeepEval, the open-source LLM evaluation framework.
From working closely with hundreds of open-source users, here were the main two challenges:
- LLM evaluation metrics are hard to make accurate and reliable. In fact, it is so tough that I previously dedicated an entire article talking about everything you need to know about LLM evaluation metrics. Most LLM evaluation metrics nowadays are LLM-Evals, which means using LLMs to evaluate LLM outputs. Although LLMs have superior reasoning capabilities that makes them great candidates for evaluating LLM outputs, they can be unreliable at times and must be carefully prompt engineered to provide a reliable score
- Evaluation datasets/test cases are hard to make comprehensive. Preparing an evaluation dataset that covers all the edge cases that might appear in a production setting is a difficult and hard to get right task. Unfortunately, it is also a very time-consuming problem, which is why I highly recommend generating synthetic data using LLMs.
So with this in mind, lets walk through how to build your own LLM evaluation framework from scratch.
Standardize AI Quality for the entire org, not just individual teams
Give all AI use cases the same quality bar with all-in-one evals, observability, and red teaming, and enforce them at scale.
Step-By-Step Guide: Building an LLM Evaluation Framework
1. Framework Setup
The first step involves setting up the infrastructure needed to make a mediocre LLM evaluation framework great. There are two components to any evaluation or testing framework: the thing to be evaluated (the “evaluatee”), and the thing we’re using to evaluate the evaluatee (the “evaluator”).
In this case, the “evaluatee” is an LLM test case, which contains the information for the LLM evaluation metrics, the “evaluator”, to score your LLM system.
To be more concrete, an LLM test case should contain parameters such as:
- Input: The input to your LLM system. Note that this does NOT include the prompt template, but literally the user input (we’ll see why later).
- Actual Output: The actual output of your LLM system for a given input. We call it “actual” output because…
- Expected Output: The expected output of your LLM system for a given input. This is where data labelers for example would give target answers for a given input.
- Context: The undisputed ground truth for a given input. Context and expected output is often time confused with one another since they are both factually similar. A good example to make things clear, is that while context could be a raw PDF page that contains everything you need to answer a question in the input, expected output is the way in which you would want the answer answered.
- Retrieval Context: The retrieved text chunks in a RAG system. As the description suggests, this is only applicable for RAG applications.
Note that only the input and actual output parameters are mandatory for an LLM test case. This is because some LLM systems might just be an LLM itself, while others can be RAG pipelines that require parameters such as retrieval context for evaluation.
The point is, different LLM architectures require different needs, but in general they are pretty much similar. Here’s how you can setup an LLM test case in code:
from typing import Optional, List
class LLMTestCase:
input: str
actual_output: str
expected_output: Optional[str] = None
context: Optional[List[str]] = None
retrieval_context: Optional[List[str]] = NoneRemember to check for type errors at runtime!
2. Implement LLM Evaluation Metrics
Probably the toughest part of building an LLM evaluation framework, which is also why I’ve dedicated an entire article talking about everything you need to know about LLM evaluation metrics.
Let’s imagine we’re building a RAG-based customer support assistant, and we want to test whether the retriever is able to retrieve relevant text chunks (aka. contextual relevancy) for a range of different user queries. In this scenario, the contextual relevancy metric is what we will be implementing, and to use it to test a wide range of user queries we’ll need a wide range of test cases with different inputs.
This is an example LLM test case:
# ...previous implementation of LLMTestCase class
test_case = LLMTestCase(
input="How much did I spend this month?"
actual_output="You spent too much this month.",
retrieval_context=["..."]
)We need a metric that gives us a contextual relevancy score based on the input and retrieval context. Note that the actual output doesn’t matter here, as generating the actual output concerns the generator, not the retriever.
As explain in a previous article, we’ll make all metrics output scores in the 0–1 range, along with a passing threshold so that you can be aware whenever a particular metric is failing on a test case. We’ll be using an QAG-based, LLM scorer to calculate the contextual relevancy score, and here’s the algorithm:
- For each node in retrieval context, use an LLM to judge whether it is relevant to the given input.
- Count all the relevant and irrelevant nodes. The contextual relevancy score will be the number of relevant nodes / total number of nodes.
- Check whether the contextual relevancy score is ≥ threshold. If it is, mark the metric as passing, and move on to the next test case.
# ...previous implementation of LLMTestCase class
class ContextualPrecisionMetric:
def __init__(self, threshold: float):
self.threshold = threshold
def measure(self, test_case: LLMTestCase):
irrelevant_count = 0
relevant_count = 0
for node in test_case.retrieval_context:
# is_relevant() will be determined by an LLM
if is_relevant(node, test_case.input):
relevant_count += 1
else:
irrelevant_count += 1
self.score = relevant_count / (relevant_count + irrelevant_count)
self.success = self.score >= self.threshold
return self.score
###################
## Example Usage ##
###################
metric = ContextualPrecisionMetric(threshold=0.6)
metric.measure(test_case)
print(metric.score)
print(metric.success)Contextual Relevancy is probably the simplest RAG retrieval metric, and you’ll notice it unsurpringly overlooks important factors such as the positioning/ranking of nodes. This is important because nodes that are more relevant should be ranked higher in the retrieval context, as it greatly affects the quality of the final output. (In fact, this is calculated by another metric called Contextual Precision.)
I’ve left the is_relevant function for you to implement, but if you’re interested in a real example here is DeepEval’s implementation of contextual relevancy.
3. Implement Synthetic Data Generator
Although this step is optional, you’ll likely find generating synthetic data more accessible than creating your own set of LLM test cases/evaluation dataset. That’s not to say generating synthetic data is a straightforward thing to do — LLM generated data can sound and look repetitive, and might not represent the underlying data distribution accurately, which is why in DeepEval we had to evolve or complicate the generated synthetic data multiple times. If you're interested in learning more about synthetic data generation, here is an article you should definitely read.
Generating synthetic data is the process of generating input-(expected)output pairs based on some given context. However, I would recommend avoid using “mediocre” (ie. non-OpenAI or Anthropic) LLMs to generate expected outputs, since it may introduce hallucinated expected outputs in your dataset.
Here is how we can create an EvaluationDataset class:
class EvaluationDataset:
def __init__(self, test_cases: List[LLMTestCase]):
self.test_cases = test_cases
def generate_synthetic_test_cases(self, contexts: List[List[str]]):
for context in contexts:
# generate_input_output_pair() will a function that uses
# an LLM to generate input and output based on the given context
input, expected_output = generate_input_output_pair(context)
test_case = LLMTestCase(
input=input,
expected_output=expected_output,
context=context
)
self.test_cases.append(test_case)
def evaluate(self, metric):
for test_case in self.test_cases:
metric.measure(test_case)
print(test_case, metric.score)
###################
## Example Usage ##
###################
metric = ContextualRelevancyMetric()
dataset = EvaluationDataset()
dataset.generate_synthetic_test_cases([["..."], ["..."]])
dataset.evaluate(metric)Again, I’ve left the LLM generation part out since you’ll likely have unique prompt templates depending on the LLM you’re using, but if you’re looking for something quick you can borrow DeepEval’s synthetic data generator, which you can pass in entire documents instead of lists of strings that you have to process yourself:
pip install deepevalfrom deepeval.dataset import EvaluationDataset
dataset = EvaluationDataset()
dataset.generate_goldens_from_docs(
document_paths=['example_1.txt', 'example_2.docx', 'example_3.pdf'],
max_goldens_per_document=2
)For the sake of simplicity, “goldens” and “test cases” can be interpreted as the same thing here, but the only difference being goldens are not instantly ready for evaluation (since they don't have actual outputs).
4. Optimize for Speed
You’ll notice that in the evaluate() method, we used a for loop to evaluate each test case. This can get very slow as it is not uncommon for there to be thousands of test cases in your evaluation dataset. What you’ll need to do, is to make each metric run asynchronously, so the for loop can execute concurrently on all test cases, at the same time. But beware, asynchronous programming can get very messy especially in environments where an event loop is already running (eg. colab/jupyter notebook environments), so it is vital to handle asynchronous errors gracefully.
Going back to the contextual relevancy metric implementation to make it asynchronous:
import asyncio
class ContextualPrecisionMetric:
# ...previous methods
########################
### New Async Method ###
########################
async def a_measure(self, test_case: LLMTestCase):
irrelevant_count = 0
relevant_count = 0
# Prepare tasks for asynchronous execution
for node in test_case.retrieval_context:
# Here, is_relevant is assumed to be async
task = asyncio.create_task(is_relevant(node, test_case.input))
tasks.append(task)
# Await the tasks and process results as they come in
for task in asyncio.as_completed(tasks):
is_relevant_result = await task
if is_relevant_result:
relevant_count += 1
else:
irrelevant_count += 1
self.score = relevant_count / (relevant_count + irrelevant_count)
self.success = self.score >= self.threshold
return self.scoreThen, change the evaluate function to make it use the asynchronous a_measure method instead:
import asyncio
class EvaluationDataset:
# ...previous methods
def evaluate(self, metric):
# Define an asynchronous inner function to handle concurrency
async def evaluate_async():
tasks = []
# Schedule a_measure for each test case to run concurrently
for test_case in self.test_cases:
task = asyncio.create_task(self.a_measure(test_case, metric))
tasks.append(task)
# Wait for all scheduled tasks to complete
results = await asyncio.gather(*tasks)
# Process results
for test_case, result in zip(self.test_cases, results):
print(test_case, result)
asyncio.run(evaluate_async())Users of DeepEval have reported that this decreases evaluation time from hours to minutes. If you’re looking to build a scalable evaluation framework, speed optimization is definitely something that you shouldn’t overlook.
Standardize AI Quality for the entire org, not just individual teams
Give all AI use cases the same quality bar with all-in-one evals, observability, and red teaming, and enforce them at scale.
5. Caching Results and Error Handling
(From this point onwards, we’ll be discussing each concept rather than diving into the specific implementation)
Here’s another common scenario — you evaluate a dataset with 1000 test cases, it fails on the 999th test case, and now you’ve to rerun 999 test cases just to finish evaluating the remaining one. Not ideal, right?
Given how costly each metric run can get, you’ll want an automated way to cache test case results so that you can use it when you need to. For example, you can design your LLM evaluation framework to cache successfully ran test cases, and optionally use it whenever you run into the scenario described above.
Caching is a bit too complicated of an implementation to include in this article, and I’ve personally spent more than a week on this feature when building on DeepEval.
Another option, is to ignore errors raised. This is much more straightforward, since you can simply wrap each metric execution in a try-catch block. But, what good is ignoring errors if you have to rerun every single test case to execute previously errored metrics?
Seriously, if you want automated, memory efficient caching for LLM evaluation results, just use DeepEval.
6. Logging Hyperparameters
The ultimate goal of LLM evaluation, is to figure out the optimal hyperparameters to use for your LLM systems. And by hyperparameters, I mean models, prompt templates, etc.
To achieve this, you must associate hyperparameters with evaluation results. This is fairly straightforward, but the difficult part actually lies in gaining metrics results based on different filters of hyperparameter combinations.
This is a UI problem, which DeepEval also solves through its integration with Confident AI. Confident AI is an evaluation platform for LLMs, and you can sign up here and try it for free.
7. CI/CD integration
Lastly, what good is an LLM evaluation framework if LLM evaluation isn’t automated? (Here is another great read on how to unit test RAG applications in CI/CD.)
You’ll need to restructure your LLM evaluation framework so that it not only works in a notebook or python script, but also in a CI/CD pipeline where unit testing is the norm. Fortunately, in the previous implementation for contextual relevancy we already included a threshold value that can act as a “passing” criteria, which you can include in CI/CD testing frameworks like Pytest.
But what about caching, ignoring errors, repeating metric executions, and parallelizing evaluation in CI/CD? DeepEval has support for all of these features, along with a Pytest integration.
Conclusion
In this article, we’ve learnt why LLM evaluation is important and how to build your own LLM evaluation framework to optimize on the optimal set of hyperparameters. However, we’ve also learnt how difficult it is to build an LLM evaluation framework from scratch, such challenges stemming from synthetic data generation, accuracy and robustness of LLM evaluation metrics, efficiency of framework, etc.
If you’re looking to learn how LLM evaluation works, building your own LLM evaluation framework is a great choice. However, if you want something robust and working, use DeepEval, we’ve done all the hard work for you already. DeepEval is free, open-source, offers 14+ research backed metrics, integration with Pytest for CI/CD, has all the optimization features discussed in this article, and comes with a free platform with a pretty UI for evaluation results.
If you’ve found this article useful, give ⭐ DeepEval a star on GitHub ⭐, and as always, till next time.
Do you want to brainstorm how to evaluate your LLM (application)? Ask us anything in our discord. I might give you an "aha!" moment, who knows?
Standardize AI Quality for the entire org, not just individual teams
Give all AI use cases the same quality bar with all-in-one evals, observability, and red teaming, and enforce them at scale.