

Picture LLMs ranging from 7 billion to over 100 billion parameters, each more powerful than the last. Among them are the giants: Mistral 7 billion, Mixtral 8x7 billion, Llama 70 billion, and the colossal Falcon 180 billion. Yet, there also exist models like Phi1, Phi1.5, and Falcon 1B, striving for similar prowess with a leaner framework of 1 to 4 billion parameters. Each model, big or small, shares a common goal: to master the art of language, excelling in tasks like summarization, question-answering, and named entity recognition.
But across all of these cases, Large Language Models (LLMs) universally share some very flawed behaviors:
- Some prompts cause LLMs to produce gibberish outputs, known as 'jailbreaking prompts'.
- LLMs are not always factually correct, a phenomenon also known as 'hallucination'.
- LLMs can exhibit unexpected behaviors that are unsafe for consumers to utilize.
It is evident that merely training LLMs is not sufficient. Thus, the question arises: How can we confidently assert that LLM 'A' (with 'n' number of parameters) is superior to LLM 'B' (with 'm' parameters)? Or is LLM 'A' more reliable than LLM 'B' based on quantifiable, reasonable observations?
There needs a standard to benchmark LLMs, ensuring they are ethically reliable and factually performant. Although a lot of research has been done on benchmarking (eg. MMLU, HellaSwag, BBH, etc.), merely researching is also not enough for robust, customized benchmarking for production use cases.
This article provides a bird's-eye view of current research on LLM evaluation, along with some outstanding open-source implementations in this area. In this blog you will learn:
- Scenarios, Tasks, Benchmark Dataset, and LLM Evaluation Metrics
- Current research on benchmarking LLM and the current problems with them
- Best practices for LLM Benchmarking/Evaluation
- Using DeepEval to enforce evaluation best practices
Scenario, Task, Benchmark Dataset, and Metric
“Scenario”, “Task”, “Benchmark Dataset” and “Metric” are some frequently used terms in the evaluation space, so it is extremely important to understand what they mean before proceeding.
Scenario
A scenario is a broad set of contexts/settings or a condition under which LLM’s performance is assessed or tested. For example:
- Question Answering
- Reasoning
- Machine Translation
- Text Generation and Natural Language Processing.
Several popular benchmarks already exist in the field of LLMs, including MMLU, HellaSwag, and BIG-Bench Hard for example.
Task
As simple as it sounds, a task can be thought of as a more granular form of a scenario. It is more specific on what basis the LLM is evaluated. A task can be a composition (or a group) of a lot of sub-tasks.
For example, Arithmetic can be considered as a task. Where it clearly mentions it evaluates LLMs on arithmetic questions. Under this, there can be a lot of sub-tasks like Arithmetic Level 1, Level 2, etc. In this example, all the arithmetic sub-tasks (from level 1 to 5) make up the Arithmetic task.
Similarly, we can have Multiple Choice as a task. Under this, we can have Multiple choice on history, algebra, etc., as all the subtasks. In fact, MMLU is based entirely on multiple choices.
Metric
A metric can be defined as a qualitative measure used to evaluate the performance of a Language Model on certain tasks/scenarios. A metric can be either a simple:
- Deterministic statistical/mathematical function (eg., Accuracy)
- Or a score produced by a Neural Network or an ML model. (eg., BERT Score)
- Or score generated by the help of LLMs itself. (eg., G-Eval)
In fact, you should read this full article if you want to learn everything about LLM evaluation metrics. For now, here is a brief overview:
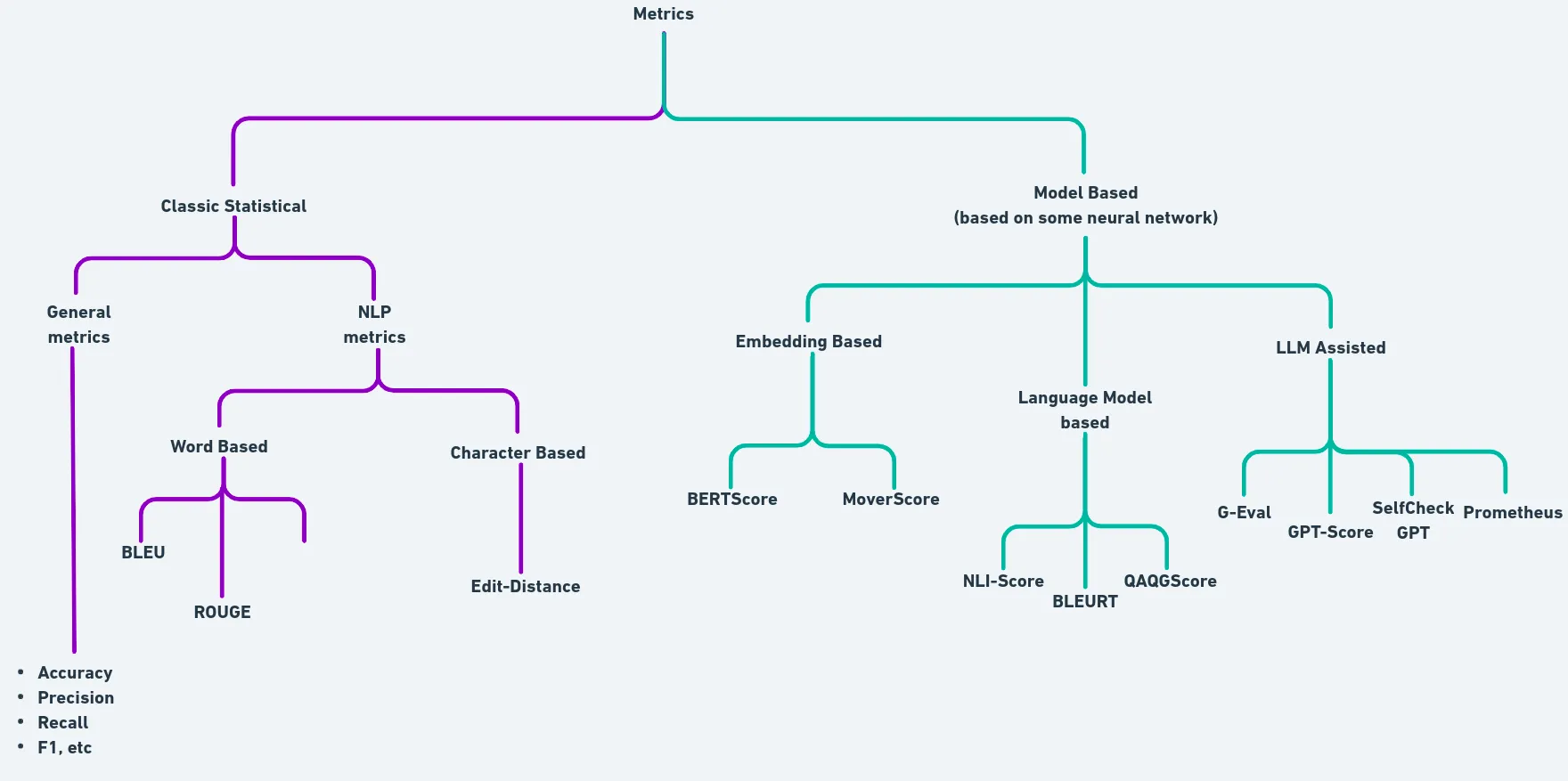
Figure 1: A simplified taxonomy of different metrics used in LLM evaluation
The above figures try to simplify the taxonomy of the classification of different types of metrics used in LLM evaluation. A metric can also be a composition of different atomic/granular metrics. A very simple example is the F1-score which is the harmonic mean of precision and recall.
Similarly in NLP, the BLEU (Bilingual Evaluation Understudy) score is a composition of precision, brevity penalty, and N-gram matching. If you wish, you can also club different metrics to come up with a new metric.
Benchmark Dataset
A benchmark dataset is a standardized collection of test sets that is used to evaluate LLMs on a given task or scenario. Here are some examples:
- SQuAD for question-answering
- GLUE for natural language understanding and Q&A
- IMDB for sentiment analysis
In most of the cases presented in later sections, you will see that a scenario can often consist of a lot of benchmark datasets. A task might consist of a lot of sub-tasks and each sub-task can consist of a bunch of datasets. But, it can also simply be a task that contain some benchmark dataset under it.
Current Research Frameworks for Benchmarking LLMs

Figure 2: Popular LLM benchmarking Framework
In this section we are going to look into various benchmarking frameworks, and what they offer. Please note: right now there is no standardization in naming conventions. It might sound very confusing when understanding this for the first time, so bear with me.
Language Model Evaluation Harness (by EleutherAI)
Language Model Evaluation Harness provides a unified framework to benchmark LLMs on a large number of evaluation tasks. I intentionally highlighted the word task, because, there is NO such concept of scenarios in Harness (I will use Harness instead of LM Evaluation Harness).
Under Harness, we can see many tasks, which contains different subtasks. Each task or set of subtasks, evaluates an LLM on different areas, like generative capabilities, reasoning in various areas, etc.
Each subtask under a task (or even sometimes the task itself) has a benchmark dataset and the tasks are generally associated with some prominent research done on evaluation. Harness puts a great effort into unifying and structuring all those datasets, configs, and evaluation strategies (like the metrics associated with evaluating the benchmark datasets), all in one place.
Not only that, Harness also supports different kinds of LLM backends (for example: VLLM, GGUF, etc). It enables huge customizability on changing prompts and experimenting with them.
This is a small example of how you can easily evaluate the Mistral model on the HellaSwag task (a task to judge the common sense capability of an LLM).
lm_eval --model hf \
--model_args pretrained=mistralai/Mistral-7B-v0.1 \
--tasks hellaswag \
--device cuda:0 \
--batch_size 8Inspired by LM Evaluation Harness, there is another framework called BigCode Evaluation Harness by the BigCode project that tries to provide similar API and CLI methods to evaluate LLMs specifically for code generation tasks. Since evaluation for code generation is a very specific topic, we can discuss that in the next blog, so stay tuned!

Figure 3: Evaluation Taxonomy structure of HELM
Standardize AI Quality for the entire org, not just individual teams
Give all AI use cases the same quality bar with all-in-one evals, observability, and red teaming, and enforce them at scale.
Stanford HELM
HELM or Holistic Evaluation of Language Model uses “scenarios” to outline where the LMs can be applied and “metrics” to specify what we want the LLMs to do in a benchmarking setting. A scenario consists of:
- A task (that aligns with the scenario)
- a domain (which consists of what genre th e text is who wrote it and when it was written)
- The language (i.e. in which language the task is)
HELM then tries to prioritize a subset of scenarios and metrics based on societal relevance (e.g. scenarios considering reliability on user-facing applications), coverage (multi-lingually), and feasibility (i.e. evaluation where a computed optimal significant subset of the task is chosen, instead of running all the datapoints one by one.)
Figure 3: Evaluation Taxonomy structure of HELM
Not only that, this HELM tries to cover a set of 7 metrics (Accuracy, Calibration, Robustness, Fairness, Bias, Toxicity, and Efficiency) for almost all the scenarios, because mere accuracy cannot provide the utmost reliability on LLM performance.
PromptBench (by Microsoft)
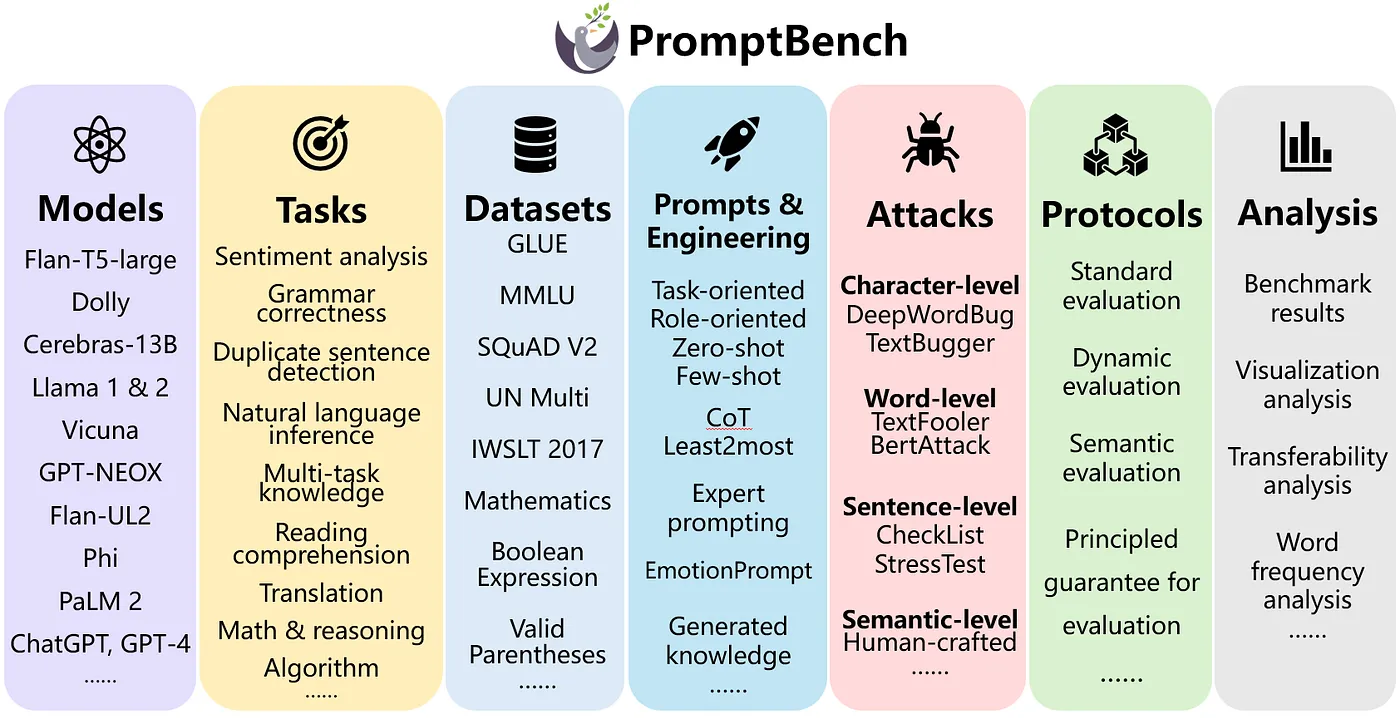
Figure 4: Microsoft Prompt Bench
PromptBench is another unified library for benchmarking LLMs. Very similar to HELM and Harness, it supports different LLM frameworks (for example: Hugging Face, VLLM, etc). What sets it apart from other frameworks is that other than just evaluating tasks, it also supports evaluating different Prompt Engineering methods and evaluates LLMs on different prompt-level adversarial attacks. We can also construct pipelines of different evaluations that make production-level use cases easier.
ChatArena (by LMSys)
Unlike previous benchmarking frameworks, this framework tries to approach the benchmarking problem differently. This benchmark platform features anonymous, randomized battles of different LLMs on specific prompts and user votes which LLM (keeping it anonymous) did the job better.
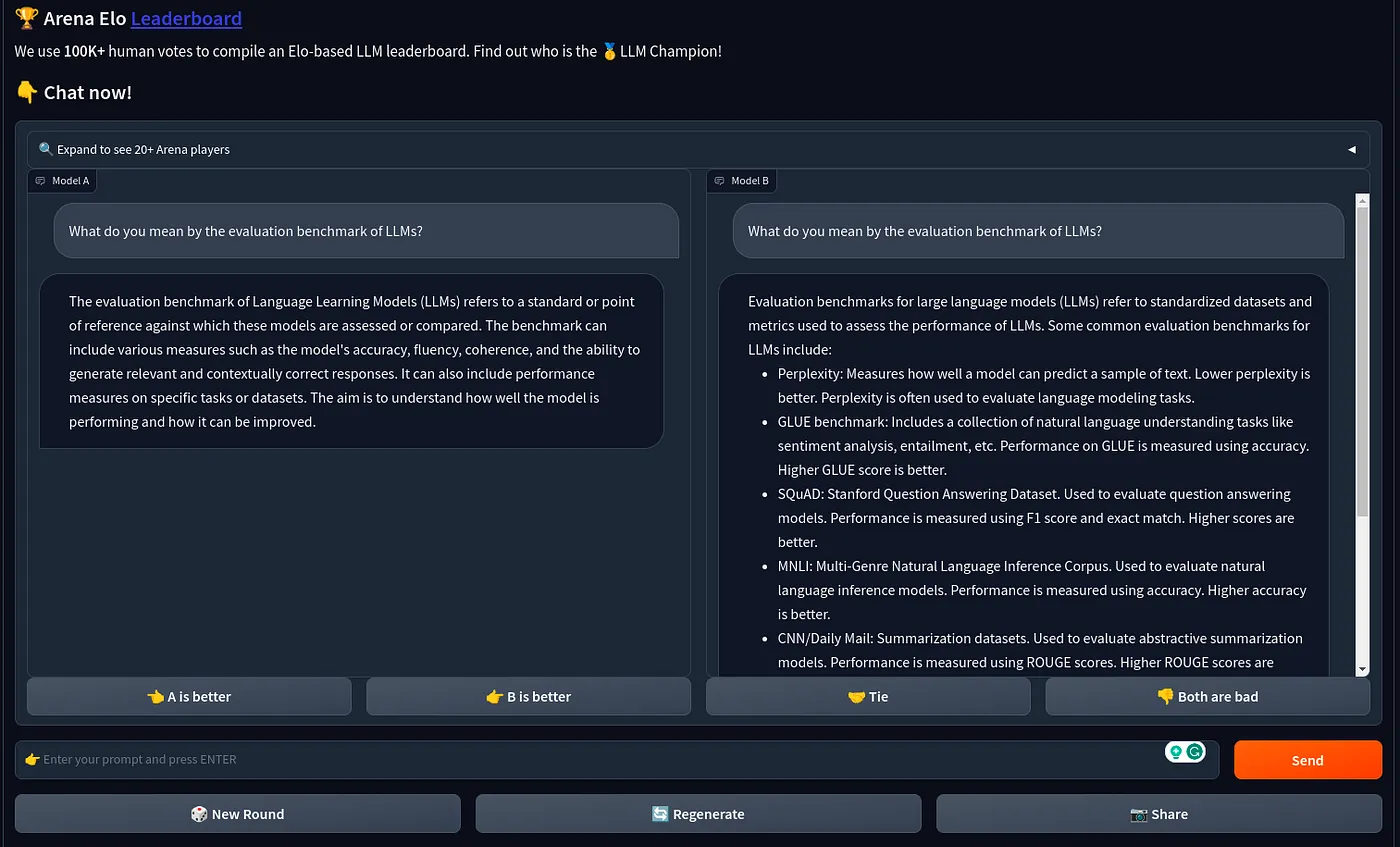
Figure 5: Chabot Arena by LMSys.
As you can see in the image above, you can start with your prompt and two anonymous LLMs (Model A and B). Both the models give some answer then you choose which model did better. Super simple and intuitive, nothing fancy. However, it does an awesome job of quantifying LLM performance. The quantification of comparison is done through Maximum Likelihood Estimation Elo (MLE-Elo) ratings (a.k.a Bradley-Terry model).
LmSys also provides a leaderboard where different major LLMs are ranked based on the MLE-Elo ratings. You can check that out here.
Still, Problems with Benchmarking LLMs Remain
Up until now, we dived into some awesome research and their various implementations. We learnt:
- How frameworks (like Harness, and HELM) came up with different taxonomies to structure the evaluation tasks.
- How different open-source platforms like Chatbot Arena makes it simple to benchmark LLMs.
- How implementations like PromptBench is more focused on production scenarios (like prompt injection attacks or adversarial attacks).
However, These systems are consisted of lots of different moving components, like vector databases, orchestration of different LLM workloads (a.k.a agents), prompt engineering, data for fine-tuning, etc., is a pain to manage.
Another problem we have is the distinction in research and production evaluation. Building and fine-tuning LLMs rapidly and shipping to production is not an easy task, and ignoring the cost and inference optimization, production-grade evaluation infrastructure is another important bottleneck. Let me explain in more detail.
As we all can agree on, testing is an important part and parcel of classical rapid software development (eg., in Python, PyTest plays an important role in testing), and is also used in CI/CD pipelines before shipping newer updates to software, and hence development process becomes streamlined and reliable.
However, we do not have a Pytest-like testing infrastructure for LLMs. Even if we have something like that, LLMs are probabilistic machines, which makes defining deterministic test cases inadequate. A thorough testing in real-time and stress testing (red teaming) is also important. But, that kind of thing is also not present right now at scale, which hinders the process of building production-grade Gen AI products.
Since LLMs need to be continuously fine-tuned, which are later used to develop LLM systems (for example RAG based systems), you need infrastructure that:
- Simultaneous evaluation during fine-tuning
- Evaluation test cases for pre/post-production
- Red teaming / Stress testing and A/B testing of LLMs and LLM systems at scale.
- Evaluation and corrections of data that will be used for LLMs.
Now at this point, if you are thinking that harness or HELM can be very useful, then you are right and wrong at the same time. Although HELM and Harness are providing users a huge leap towards evaluating LLMs, all of these libraries have shadow interfaces (API interfaces that are not mentioned properly in the documentation) and mostly use or run through CLI, which is not ideal for the rapid prototyping of models.
Lastly, we might require very domain-specific evaluations that is out-of-scope of these current benchmarking frameworks. Writing those evaluations should be as easy as writing test cases for PyTest, and the same goes for benchmarking LLMs, which these frameworks do not currently support.
Best Practices in Benchmarking LLMs
Although this whole field is very much new, we are seeing and emerging trend that practitioners are mostly using LLMs for very specific use cases such as text summarization, QA on internal knowledge bases, and data extraction. In most cases, LLMs need to be benchmarked on how faithful they are, and also they need to be benchmarked on how accurate they are in the domain on which they will be deployed.
So, a typical development lifecycle:
- Starts with an existing open-source LLM or a closed-source LLM.
- Adapts your LLM to the desired use case. We can do this by either doing some prompt engineering (like Chain of Thoughts or using In-Context Learning), or using vector databases in RAG to provide more contexts. We can fine-tune the LLM and use the previous methods along with it to get the full performance out of the LLM.
- Put into production with additional guardrailing of LLMs, and connecting it with the backend server to get the data as their input.
The above set of processes can be divided into two phases.
- Pre-production evaluation.
- Post-production evaluation.
Pre-Production Evaluation
During this initial exploration phase, we can experiment with each of the following combinations:
- LLM + prompt engineering (like CoT or In-Context Learning).
- LLM + prompt engineering + RAG.
- Fine-tuning LLM + prompt engineering + RAG, etc works the best.
Since working with LLMs is a costly business, we need to keep a perfect balance between cost and quality. So experimentation is a huge part of this process. We also need to have proper evaluation infrastructure that:
- can evaluate the LLMs on different prompts and have a place where we can rank which prompt combinations work the best.
- can evaluate the retrieval engines (which consist of retrieval models) in RAG-based use cases to understand how factually correct contexts are retrieved before feeding to the LLM.
- can evaluate different fine-tuning checkpoints (that are made during fine-tuning of the LLMs) and evaluate which checkpoints work the best.
- can have some standardized scores from HELM or Harness (i.e. from their standardized benchmark dataset that falls under the target domain). This is important so that we can have an evaluation scorecard (very similar to model cards or dataset cards), which is universal and becoming standardized.
- can evaluate a custom domain-specific private benchmark dataset so that we can be fully sure of how the LLM is performing on data that will be similar during production.
- can evaluate how reliable the LLMs are (i.e. the LLMs should not be toxic or unfaithful or should not be able to prompt high jacked, etc.) and how accurate it is (i.e. how factually correct the LLM is).
- can evaluate different pipelines (as mentioned in the above combinations) to understand which pipeline combination works the best.
- last but not least rigorous
of the LLMs is very much required (specifically for chat-based models) before putting it into production.
Post-Production Evaluation
Once LLMs are deployed, here are some very important best practices that can be employed after putting LLM pipelines into production:
- Continuous monitoring of LLMs. This is very important so that we can maintain near-realtime-altering systems for unsatisfactory outputs of LLM apps. This also helps to understand what went wrong easily and fix it.
- Explicit feedback such as indicators (eg., user thumbs up/down rating) to give feedback to the LLM generation.
- Supporting continuous fine-tuning of the LLM (along with the embedding models used in RAG-based applications) and continuous deployment to maintain customer-centric generations, otherwise the application might face eventual data drifts.
Implementing Best Practices for LLM Benchmarking
If you want to practice building a testing framework for LLMs, implementing everything from scratch is a great choice. However, if you want to use an existing robust evaluation framework for LLMs, use DeepEval, as we've done all the hard work for you already.
DeepEval is the open-source evaluation infrastructure for LLMs, and makes following best practices for evaluation processes as easy as writing test cases in PyTest. Here are the things it offers to solve current problems with benchmarking LLMs:
- Integrated with PyTest, so it provides you with a very similar interface and decorators in Pytest so that you can write domain-specific test cases for evaluating LLMs for use cases that current benchmarking frameworks don't cover.
- Offers 14+ pre-defined metrics to evaluate LLMs/RAG-based systems, that runs both locally on your machine or using GPT models. Users are also free to write their own customized evaluation metrics, which are all automatically integrated with DeepEval's evaluation ecosystem.
- Push evaluation results to Confident AI, DeepEval's hosted platform, that allows you to keep track of evaluation experiments, debug evaluation results, centralize benchmarking datasets for evaluation, and track production events to continuously evaluate LLMs via different reference-less metrics.
Not only that, but several new features like integration of LM-Evaluation Harness, and concurrent evaluations during fine-tuning using HuggingFace are coming soon. If you want to understand more about DeepEval, check out the ⭐ GitHub repo ⭐
from deepeval import assert_test
from deepeval.metrics import HallucinationMetric
from deepeval.test_case import LLMTestCase
def test_hallucination():
metric = HallucinationMetric(minimum_score=0.5)
test_case = LLMTestcase(input="...", actual_output="...")
assert_test(test_case, [metric])Don’t forget to give it a star to let us know we're moving in the right direction. Also, we have a curated set of docs and tutorials where you can easily get started with DeepEval.
Conclusion
In this article, we learned about the current evaluation paradigm and understood terminologies of LLM benchmarking/evaluation. We also learned about some prominent research on evaluating benchmarking and comparing LLMs on various tasks or scenarios. Finally, we discussed the current problems of evaluating LLMs during a production use case and also went through some best practices that can help us overcome the commonly seen production-related issues and deploy LLMs safely and confidently.
References
- LM Evaluation Harness
- Language Models are Changing AI: The Need for Holistic Evaluation
- Lightning Talks on LLM Evaluation: By Anindyadeep
- Code Generation Evaluation Harness
- Everything you need to know about LLM Guadrails.
- Best practices for deploying LLMs by Open AI.
Do you want to brainstorm how to evaluate your LLM (application)? Ask us anything in our discord. I might give you an “aha!” moment, who knows?
Do you want to brainstorm how to evaluate your LLM (application)? Ask us anything in our discord. I might give you an "aha!" moment, who knows?
Standardize AI Quality for the entire org, not just individual teams
Give all AI use cases the same quality bar with all-in-one evals, observability, and red teaming, and enforce them at scale.