

Just earlier this month, Anthropic unveiled their latest Claude-3 Opus model, which was preceded by Mistral's Le Large model a week prior, which was again preceded by Google's Gemini Ultra 1.5, which was of course released shortly right after Ultra 1.0. With more LLMs than ever being released at breakneck speed, it is now imperative to quantify LLM performance on a standard set of tasks. So the question is, how?
LLM benchmarks offer a structured framework for evaluating LLMs across a variety of tasks. Understanding when and how to leverage them is crucial not just for comparing models, but also for building a reliable and fail-safe model.
In this article, I’m going to walk you through everything you need to know about LLM benchmarks. We‘ll explore:
- What LLM benchmarks are and how to pick the one for your needs.
- All the key benchmarks in technical reports and industry. (MMLU, HellaSwag, BBH, etc.)
- The limitations of LLM benchmarks, and ways to get around them by generating synthetic datasets.
What are LLM Benchmarks?
LLM benchmarks such as MMLU, HellaSwag, and DROP, are a set of standardized tests designed to evaluate the performance of LLMs on various skills, such as reasoning and comprehension, and utilize specific scorers or metrics to quantitatively measure these abilities. Depending on the benchmark, metrics may range from statistics-based measures, such as the proportion of exact matches, to more intricate metrics evaluated by other LLMs. (In fact, here is a great article on everything you need to know about LLM evaluation metrics)
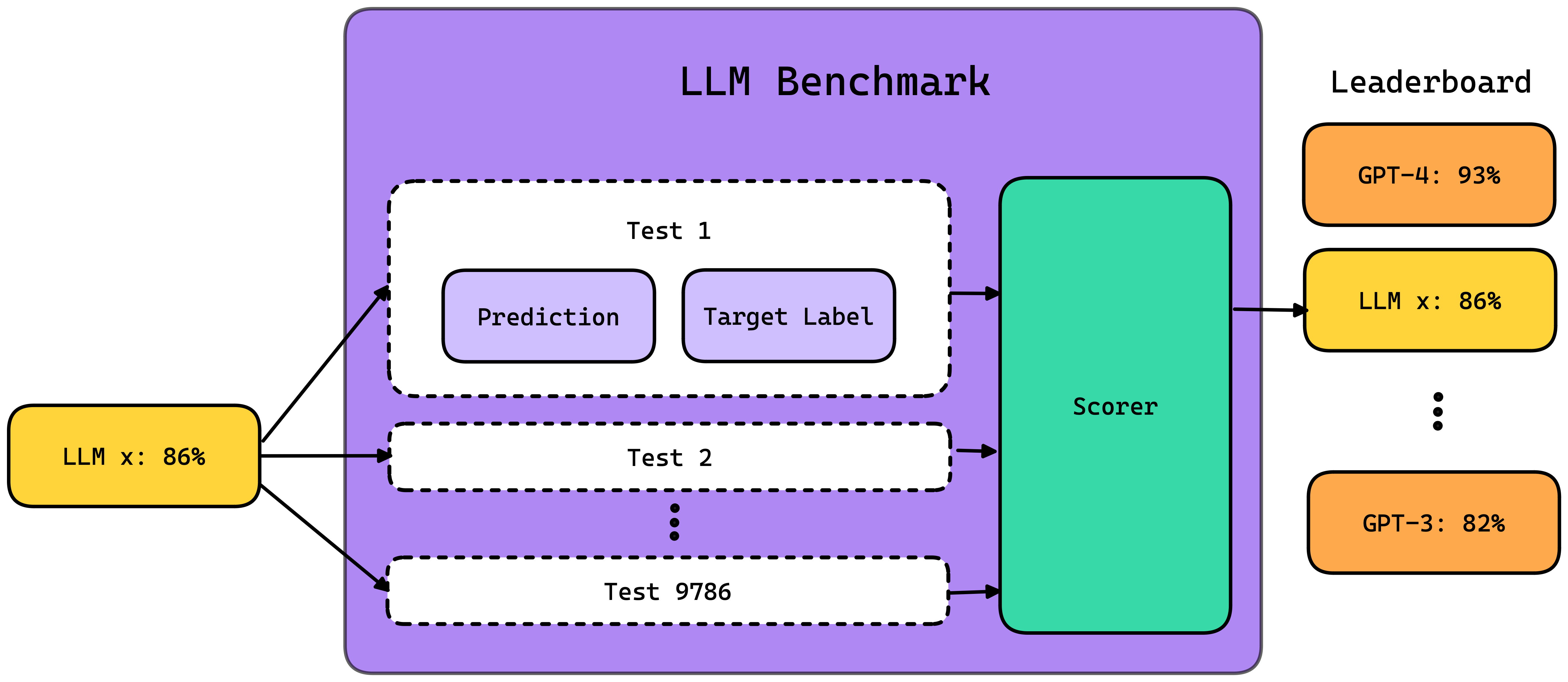
An LLM Benchmark Architecture
Different benchmarks assess various aspects of a model’s capabilities, including:
- Reasoning and Commonsense: These benchmarks test an LLM’s ability to apply logic and everyday knowledge to solve problems.
- Language Understanding and Question Answering (QA): These evaluate a model’s ability to interpret text and answer questions accurately.
- Coding: Benchmarks in this category evaluate LLMs on their ability to interpret and generate code.
- Conversation and Chatbots: These tests an LLM’s ability to engage in dialogue and provide coherent, relevant responses.
- Translation: These assess the model’s ability to accurately translate text from one language to another.
- Math: These focus on a model’s ability to solve math problems, from basic arithmetic to more complex areas such as calculus.
- Logic: Logic benchmarks evaluate a model’s ability to apply logical reasoning skills, such as inductive and deductive reasoning.
- Standardized Tests: SAT, ACT, or other educational assessments are also used to evaluate and benchmark the model’s performance.

LLM Benchmark Categories
Some benchmarks may have just a few dozen tests, while others could have hundreds or even thousands of tasks. What’s important is that LLM benchmarking provides a standardized framework for evaluating LLM performance across different domains and tasks. However, this is NOT equivalent to LLM system benchmarks, which are custom to your LLM application.
Choosing the right benchmarks for your project means:
- Aligning with Objectives: Making sure the benchmarks match up with the specific tasks your LLM needs to excel at.
- Embracing Task Diversity: Seeking out benchmarks with a broad spectrum of tasks gives you a well-rounded assessment of your LLM.
- Staying Domain-Relevant: Selecting benchmarks that resonate with your application’s world, whether that’s understanding language, spinning up text, or coding.
Think of them as the SAT for high school students, but for LLMs. While they can’t assess every possible aspect of a model’s capabilities, they certainly provide valuable insights. Here’s how Claude 3’s performance compares with other state-of-the-art (SOTA) models across several benchmarks.
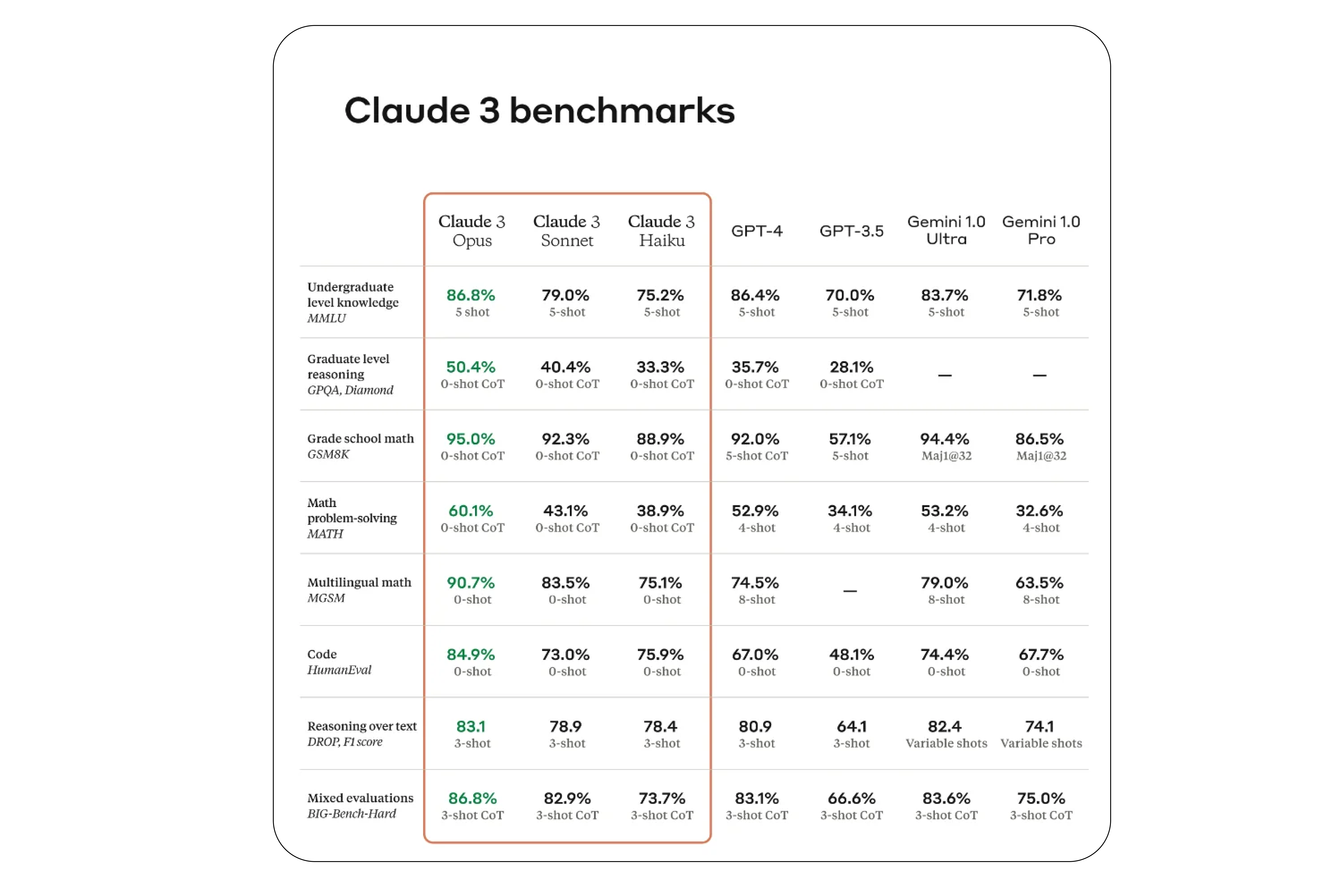
Claude-3 Benchmark Results
Don’t worry if you don’t know what MMLU, HellaSwag, and some of these other benchmarks mean, we’re going to dive into this in the next section.
Different Types of LLM Benchmarks
In the following section, I’ll be discussing 8 key LLM Benchmarks across the 4 most critical domains (Language Understanding, Reasoning, Coding, and Conversation). These benchmarks are widely utilized in industry applications and are frequently cited in technical reports. They include:
- TruthfulQA — Truthfulness
- MMLU — Language understanding
- HellaSwag — Commonsense reasoning
- BIG-Bench Hard — Challenging reasoning tasks
- HumanEval — Coding challenges
- CodeXGLUE — Programming tasks
- Chatbot Arena — Human-ranked ELO-based benchmark
- MT Bench — Complex conversational ability
Standardize AI Quality for the entire org, not just individual teams
Give all AI use cases the same quality bar with all-in-one evals, observability, and red teaming, and enforce them at scale.
Language Understanding and QA Benchmarks
TruthfulQA
[Published in 2022] ∙ Paper ∙ Code ∙ Dataset

Sample questions from TruthfulQA (Suzgun et al.)
TruthfulQA evaluates models on their ability to provide accurate and truthful answers, which is crucial for combating misinformation and promoting ethical AI usage.
The original dataset contains 817 questions across 38 categories, including health, law, finance, and politics. These questions are specifically designed to target areas where humans might provide incorrect answers due to false beliefs or misconceptions. In fact, the best-performing model in the original paper, GPT-3, achieved only a 58% success rate compared to the human baseline of 94%.
The final score is calculated based on the proportion of truthful outputs a model generates. A fine-tuned GPT-3 (“GPT-Judge”) scorer is used to determine the truthfulness of an answer!
If TruthfulQA sounds inaccessible to you, I have some good news. We've implemented several key benchmarks inside DeepEval, the open-source LLM evaluation framework, so that you can easily benchmark any LLM of your choice in just a few lines of code.
First install DeepEval:
pip install deepevalAnd run the benchmark:
from deepeval.benchmarks import TruthfulQA
from deepeval.benchmarks.modes import TruthfulQAMode
# Define benchmark with specific shots
benchmark = TruthfulQA(mode=TruthfulQAMode.MC2)
# Replace 'mistral_7b' with your own custom model
benchmark.evaluate(model=mistral_7b)
print(benchmark.overall_score)For more information, check the documentation.
MMLU (Massive Multitask Language Understanding)
[Published in 2021] ∙ Paper ∙ Code ∙ Dataset

Sample question from the MMLU Microeconomics Task.
MMLU is aimed at evaluating models based on the knowledge they acquired during pre-training, focusing solely on zero-shot and few-shot settings.
It’s a comprehensive benchmark that evaluates models on multiple choice questions across 57 subjects, including STEM, humanities, social sciences, and more, with difficulty levels ranging from elementary to advanced. The wide range and detail of the subjects make this benchmark perfectly for identifying any gaps in a model’s knowledge within specific areas.
MMLU scores an LLM simply based on the proportion of correct answers. The output must be an exact match to be considered correct (‘D’ for the above example).
Here is how you can use the HellaSwag benchmark through DeepEval:
from deepeval.benchmarks import MMLU
from deepeval.benchmarks.tasks import MMLUTask
# Define benchmark with specific tasks and shots
benchmark = MMLU(
tasks=[MMLUTask.HIGH_SCHOOL_COMPUTER_SCIENCE, MMLUTask.ASTRONOMY],
n_shots=3
)
# Replace 'mistral_7b' with your own custom model
benchmark.evaluate(model=mistral_7b)
print(benchmark.overall_score)For more implementation details, visit the DeepEval MMLU docs.
Additional noteworthy language understanding and QA benchmarks: GLUE, SuperGLUE, SQuAD, and GPT tasks, CoQA, QuAC, TriviaQA, DROP
Common-sense and Reasoning Benchmarks
HellaSwag
[Published in 2019] ∙ Paper ∙ Code ∙ Dataset

Sample question from HellaSwag (Zellers et. al)
HellaSwag evaluates the common-sense reasoning capabilities of LLM models through sentence completion. It tests whether LLM models can select the appropriate ending from a set of 4 choices across 10,000 sentences.
While SOTA models at the time struggled to score above 50% with pre-training, GPT-4 achieved a record-high of 95.3% with just 10-shot prompting in 2023. Similar to MMLU, HellaSwag scores LLMs based on their proportion of exact correct answers.
Here is how you can use the HellaSwag benchmark through DeepEval:
from deepeval.benchmarks import HellaSwag
from deepeval.benchmarks.tasks import HellaSwagTask
# Define benchmark with specific tasks and shots
benchmark = HellaSwag(
tasks=[HellaSwagTask.TRIMMING_BRANCHES_OR_HEDGES, HellaSwagTask.BATON_TWIRLING],
n_shots=5
)
# Replace 'mistral_7b' with your own custom model
benchmark.evaluate(model=mistral_7b)
print(benchmark.overall_score)Visit the DeepEval's HellaSwag documentation page for more information about this implementation.
BIG-Bench Hard (Beyond the Imitation Game Benchmark)
[Published in 2022] Paper ∙ Code ∙ Dataset
BIG-Bench Hard (BBH) selects 23 challenging tasks from the original BIG-Bench suite, which consisted of a diverse evaluation set of 204 tasks already beyond the capabilities of language models at the time.

Standard (few-shot) prompting vs CoT Prompting (Wei et. al)
At the time BIG-Bench was published, not a single SOTA language model managed to surpass the average human evaluator across any of these 23 tasks. Interestingly, the authors of BBH were able to outperform humans on 17 of these tasks with the same exact LLMs using Chain-of-Thought (CoT) prompting.
While BBH expected outputs are much more varied than other multiple-choice question based benchmarks, it also scores models based on proportion of exact matches. CoT prompting helps confine the model outputs to the expected format.
To use the BBH benchmark:
from deepeval.benchmarks import BigBenchHard
from deepeval.benchmarks.tasks import BigBenchHardTask
# Define benchmark with specific tasks and shots
benchmark = BigBenchHard(
tasks=[BigBenchHardTask.BOOLEAN_EXPRESSIONS, BigBenchHardTask.CAUSAL_JUDGEMENT],
n_shots=3,
enable_cot=True
)
# Replace 'mistral_7b' with your own custom model
benchmark.evaluate(model=mistral_7b)
print(benchmark.overall_score)Again, you can find more information on DeepEval's BBH documentation page.
Additional Noteworthy common-sense and reasoning benchmarks: ARC, CommonsenseQA, COPA, SNLI, MultiNLI, RACE, ANLI, PIQA, COSMOS QA
Standardize AI Quality for the entire org, not just individual teams
Give all AI use cases the same quality bar with all-in-one evals, observability, and red teaming, and enforce them at scale.
Coding Benchmarks
HumanEval
[Published in 2021] Paper ∙ Code ∙ Dataset
HumanEval consists of 164 unique programming tasks designed to evaluate a model’s code generation abilities. These tasks cover a broad spectrum, from algorithms to the comprehension of programming languages.
Below is an example task from a collection similar to HumanEval, along with a solution generated by a model:
Task Description: Write a function
*sum_list*that takes a list of numbers as an argument and returns the sum of all numbers in the list. The list can contain integers and floating-point numbers.
Generated code:
def sum_list(numbers: List[float]) -> float:
return sum(numbers)HumanEval scores the quality of generated code using the Pass@k Metric, which is designd to emphasize functional correctness in addition to basic textual similarity.
from deepeval.benchmarks import HumanEval
# Define benchmark with number of code generations
benchmark = HumanEval(n=100)
# Replace 'gpt_4' with your own custom model
benchmark.evaluate(model=gpt_4, k=10)
print(benchmark.overall_score)CodeXGLUE
[Published in 2021] Paper ∙ Code ∙ Dataset ``

Example of line-level code completion task in CodexGLUE from (Lu et. al)
CodeXGLUE offers 14 datasets across 10 different tasks to test and compare models directly in various coding scenarios such as code completion, code translation, code summarization, and code search. It was developed as a collaboration between Microsoft, Developer Division, and Bing.
CodeXGLUE evaluation metrics vary from exact match to BLUE score depending on the coding task.
Additional noteworthy coding benchmarks: CodeBLEU, MBPP, Py150, MathQA, Spider, DeepFix, Clone Detection, CodeSearchNet
Conversation and Chatbot Benchmarks
Chatbot Arena
[Published in 2024] Paper ∙ Code
The Chatbot Arena is an open platform for ranking language models using over 200K human votes. Users can anonymously quiz and judge pairs of AI models like ChatGPT or Claude without knowing their identities, and votes are counted towards rankings only if the model identities stay hidden. So it’s not a traditional benchmark where a metric is used to objectively score a model! The score is essentially the number of “upvotes”.

Chatbot Arena
MT Bench
[Published in 2021] Paper ∙ Code ∙ Dataset

Sample question from MTBench from (Zheng et. al)
MT-bench evaluates chat assistants’ quality by presenting them with a series of multi-turn open-ended questions, utilizing LLMs as judges. This approach tests chat assistants’ ability to handle complex interactions. MT-Bench uses GPT-4 to score on a conversation on a scale of 10, and compute the average score on all turns to get the final score.
All these benchmarks are extremely useful in assessing certain skills, but what if the existing benchmarks don’t quite match your project’s unique needs?
Additional noteworthy conversation and chatbot benchmarks: DSTC, ConvAI, PersonaChat
Standardize AI Quality for the entire org, not just individual teams
Give all AI use cases the same quality bar with all-in-one evals, observability, and red teaming, and enforce them at scale.
Limitations of LLM Benchmarks
While benchmarks are fundamental to assessing the capabilities of LLMs, they come with their own set of limitations:
- Domain Relevance: Benchmarks often fall short in aligning with the unique domains and contexts where LLMs are applied, lacking the specificity needed for tasks like legal analysis or medical interpretation. This gap highlights the challenge in creating benchmarks that accurately assess LLM performance across a broad spectrum of specialized applications.
- Short Life Span: When benchmarks first roll out, it usually turns out that models aren’t quite up to par with the human baseline. But give it a bit of time — say, 1–3 years — and advanced models make the initial challenges seem like a walk in the park (case in point). When these metrics no longer offer a challenge, it becomes necessary to develop new benchmarks that are useful.
Nevertheless, it’s not all doom and gloom. It is possible to overcome these limitations through innovative approaches such as synthetic data generation.
Customizing an LLM Benchmark
Benchmarking LLMs are difficult because standard benchmarks cannot account for your specific use case. A workaround, would be to generate synthetic benchmarks for your specific use case using data in your knowledge base as context.

A data synthesizer architecture
Synthetic data generation is the process of essentially creating data from scratch, which has become increasingly possible thanks to advancements in LLMs. This method enables us to continually create custom benchmarks tailored to our specific tasks, ensuring domain relevance and also eliminating the problem of short lifespans.
Conveniently, DeepEval also allows you to generate synthetic data that can then be used in your benchmark dataset:
from deepeval.synthesizer import Synthesizer
synthesizer = Synthesizer()
contexts = [
["The Earth revolves around the Sun.", "Planets are celestial bodies."],
["Water freezes at 0 degrees Celsius.", "The chemical formula for water is H2O."],
]
synthesizer.generate_goldens(contexts=contexts)
synthesizer.save_as(
file_type='json',
path="./synthetic_data"
)In DeepEval, a golden is simply an input-expected output pair. In the world of benchmarking, the expected output is also known as the target labels.
With this setup, you’ve now successfully generated a synthetic dataset and saved it to a local .json file in the ./synthetic_data directory. This custom dataset can be used to benchmark and evaluate the performance of your LLMs, offering critical insights into their strengths and areas for enhancement.
For a detailed guide on leveraging DeepEval to create your custom benchmarks, keep an eye out for next week’s article. I will be delving deeply into the process of generating synthetic data.
Conclusion
Congratulations on making it this far! To recap, we’ve discussed what LLM benchmarks are, explored the commonly used benchmarks such as MMLU, HellaSwag and BIG-Bench Hard, which can all be accessed through DeepEval to evaluate any custom LLM of your choice. (If you think DeepEval is useful, give it ⭐ a star on GitHub ⭐ to keep track of new releases as we roll out supporting for more benchmarks.)
We also saw how many benchmarks aren’t specific enough to provide a comprehensive assessment of LLMs in niche areas, hindering their effectiveness. Moreover, the rapid pace of technological progress in LLMs means benchmarks need to be constantly updated to stay relevant. To tackle this problem, synthetic data generation emerges as a valuable solution, enabling the creation of adaptable, domain-specific benchmarks. This strategy ensures that the custom benchmarks stay relevant over time and that LLM developers can continually improve their models’ performances.
Do you want to brainstorm how to evaluate your LLM (application)? Ask us anything in our discord. I might give you an "aha!" moment, who knows?
Standardize AI Quality for the entire org, not just individual teams
Give all AI use cases the same quality bar with all-in-one evals, observability, and red teaming, and enforce them at scale.