

Introducing OpenAI API, and lLamaindex
In this tutorial, we're going to use GPT-3.5 provided by the OpenAI API. GPT-3.5 is a machine learning model and is like a super-smart computer buddy made by OpenAI. It's been trained with tons of data from the internet so it can chat, answer questions, and help with all sorts of language tasks.
But, you might wonder, can raw, out-of-the-box GPT-3.5 answer customer support questions that are specific to my own internal data?
Unfortunately, the answer is no 😔 because as you may know, GPT models have only been trained on public data up until 2021. This is precisely why we need open source frameworks like lLamaIndex! These frameworks help connect your internal data sources with GPT-3.5, so your chatbot can output tailored responses based on data that regular ChatGPT don't know about 😊 (PS. if you want to learn how to use the raw OpenAI API to build a chatbot instead of a framework like lLamaIndex, here is another great tutorial.)
Pretty cool, huh? Lets begin.
Project Setup 🚀
First, I'll guide you through how to set up a project for your chatbot.
Create the project folder and a python virtual environment by running the code below in terminal:
mkdir customer-support-chatbot
cd customer-support-chatbot
python3 -m venv venv
source venv/bin/activateYour terminal should now start something like this:
(venv)Installing dependencies
Run the following code to install lLamaIndex:
pip install llama-indexNote that we don't require openai because lLamaIndex already provides a wrapper to call the OpenAI API under the hood.
Create a new main.py file - the entry point to your chatbot, and chatbot.py - your chatbot implementation.
touch main.py chatbot.pySetting up your internal knowledge base
Create a new data.txt file in a new data folder that would contain fake data on MadeUpCompany:
mkdir data
cd data
touch data.txtThis file will contain the data that your chatbot is going to base its responses on. Luckily for us, ChatGPT prepared some fake information on MadeUpCompany 😌 Paste the following text in data.txt:
MadeUpCompanyMadeUpCompany is a pioneering technology firm founded in 2010, specializing in cloud computing, data analytics, and machine learning. Our headquarters is based in San Francisco, California, with satellite offices spread across New York, London, and Tokyo. We are committed to offering state-of-the-art solutions that help businesses and individuals achieve their full potential. With a diverse team of experts from various industries, we strive to redefine the boundaries of innovation and efficiency.Products and ServicesWe offer a suite of services ranging from cloud storage solutions, data analytics platforms, to custom machine learning models tailored for specific business needs. Our most popular product is CloudMate, a cloud storage solution designed for businesses of all sizes. It offers seamless data migration, top-tier security protocols, and an easy-to-use interface.
Our data analytics service, DataWiz, helps companies turn raw data into actionable insights using advanced algorithms.PricingWe have a variety of pricing options tailored to different needs. Our basic cloud storage package starts at $9.99 per month, with premium plans offering more storage and functionalities. We also provide enterprise solutions on a case-by-case basis, so it’s best to consult with our sales team for customized pricing.
Technical SupportOur customer support team is available 24/7 to assist with any technical issues. We offer multiple channels for support including live chat, email, and a toll-free number. Most issues are typically resolved within 24 hours. We also have an extensive FAQ section on our website and a community forum for peer support.Security and ComplianceMadeUpCompany places the utmost importance on security and compliance. All our products are GDPR compliant and adhere to the highest security standards, including end-to-end encryption and multi-factor authentication.Account ManagementCustomers can easily manage their accounts through our online portal, which allows you to upgrade your service, view billing history, and manage users in your organization. If you encounter any issues or have questions about your account, our account management team is available weekdays from 9 AM to 6 PM.Refund and Cancellation Policy
We offer a 30-day money-back guarantee on all our products. If you're not satisfied for any reason, you can request a full refund within the first 30 days of your purchase. After that, you can still cancel your service at any time, but a prorated refund will be issued based on the remaining term of your subscription.Upcoming FeaturesWe’re constantly working to improve our services and offer new features.
Keep an eye out for updates on machine learning functionalities in DataWiz and more collaborative tools in CloudMate in the upcoming quarters.Your customer support staff can use these paragraphs to build their responses to customer inquiries, providing both detailed and precise information to address various questions.Lastly, navigate back to customer-support-chatbot containing main.py, and set your OpenAI API key as an environment variable. In your terminal, paste in this with your own API key (get yours here if you don't already have one):
export OPENAI_API_KEY="your-api-key-here"All done! Let's start coding.
Building a Chatbot with lLamaIndex 🦄
To begin, we first have to chunk and index the text we have in data.txt to a format that's readable for GPT-3.5. So you might wonder, what do you mean by "readable"? 🤯
Well, GPT-3.5 has something called a context limit, which refers to how much text the model can "see" or consider at one time. Think of it like the model's short-term memory. If you give it a really long paragraph or a big conversation history, it might reach its limit and not be able to add much more to it. If you hit this limit, you might have to shorten your text so the model can understand and respond properly.
In addition, GPT-3.5 performs worse if you supply it with way too much text, kind of how someone loses focus if you tell too long a story. This is exactly where lLamaIndex shines 🦄 llamaindex helps us breakdown large bodies of text into chunks that can be consumed by GPT-3.5 🥳

In a few lines of code, we can build our chatbot using lLamaIndex. Everything from chunking the text from data.txt, to calling the OpenAI APIs, is handled by lLamaIndex. Paste in the following code in chatbot.py:
from llama_index import VectorStoreIndex, SimpleDirectoryReader
documents = SimpleDirectoryReader('data').load_data()
index = VectorStoreIndex.from_documents(documents)
query_engine = index.as_query_engine()
def query(user_input):
return query_engine.query(user_input).responseAnd the following in main.py:
from chatbot import query
while True:
user_input = input("Enter your question: ")
response = query(user_input)
print("Bot response:", response)Now try it for yourself by running the code below:
python3 main.pyFeel free to switch out the text in data/data.txt with your own knowledge base!
Improving your Chatbot
You might start to run into situations where the chatbot isn't performing as well as you hope for certain questions/inputs. Luckily there are several ways to improve your chatbot 😊
Parsing your data into smaller/bigger chunks
The quality of output from your chatbot is directly affected by the size of text chunks (scroll down for a better explanation why).
In chatbot.py, Add service_context = ServiceContext.from_defaults(chunk_size=1000) to VectorStoreIndex to alter the chunk size:
from llama_index import VectorStoreIndex, SimpleDirectoryReader
from llama_index import ServiceContext
service_context = ServiceContext.from_defaults(chunk_size=1000)
documents = SimpleDirectoryReader('data').load_data()
index = VectorStoreIndex.from_documents(documents)
query_engine = index.as_query_engine()
def query(user_input):
return query_engine.query(user_input).responsePlay around with the size parameter to find what works best :)
Providing more context to GPT-3.5
Depending on your data, you might benefit from supply a lesser/greater number of text chunks to GPT-3.5. Here's how you can do it through query_engine = index.as_query_engine(similarity_top_k=5) in chatbot.py:
from llama_index import VectorStoreIndex, SimpleDirectoryReader
from llama_index import ServiceContext
service_context = ServiceContext.from_defaults(chunk_size=1000)
documents = SimpleDirectoryReader('data').load_data()
index = VectorStoreIndex.from_documents(documents)
query_engine = index.as_query_engine(similarity_top_k=5)
def query(user_input):
return query_engine.query(user_input).responseStandardize AI Quality for the entire org, not just individual teams
Give all AI use cases the same quality bar with all-in-one evals, observability, and red teaming, and enforce them at scale.
Evaluating your chatbot ⚖️
By now, you might have ran into the problem of eyeballing your chatbot output. You make a small configurational change, such as changing the number of retrieved text chunks, run main.py, type in the same old query, and wait 5 seconds to see if the result has gotten any better 😰 Sounds familiar?
The problem becomes worse if you want to inspect outputs from not just one, but several different queries. Here is a great read on how you can build your own evaluation framework in less than 20 minutes, but if you'd prefer to not reinvent the wheel, consider using a free open source packages like DeepEval. It helps you evaluate your chatbot so you don't have to do it yourself 😌
Since I'm slightly biased as the cofounder of Confident AI (which is the company behind DeepEval), I'm going to go ahead and show you how DeepEval can help with evaluating your chatbot (no but seriously, we offer unit testing for chatbots, have a stellar developer experience, and a free platform for you to holistically view your chatbot's performance 🥵)
Install by running the code:
pip install deepevalCreate a new test file:
touch test_chatbot.pyPaste in the following code:
import pytest
from chatbot import query
from deepeval.metrics import HallucinationMetric
from deepeval.test_case import LLMTestCase
from deepeval import assert_test
def test_chatbot():
hallucination_metric = FactualConsistencyMetric(minimum_score=0.7)
test_case = LLMTestCase(
input="What does your company do?",
actual_output=query(input),
context=[
"Our company specializes in cloud computing, data analytics, and machine learning. We offer a range of services including cloud storage solutions, data analytics platforms, and custom machine learning models."
]
)
assert_test(test_case, [hallucination_metric])Run the test:
deepeval test run test_chatbot.pyYour test should have passed! Let's breakdown what happened. The variable input mimics a user input, and actual_output is what your chatbot outputs based on this query. The variable context contains the relevant information from your knowledge base, and HallucinationMetric(minimum_score=0.7) is an out-of-the-box metric provided by DeepEval for your to assess how factually correct your chatbot's output is based on the provided context. This score ranges from 0 - 1, which the minimum_score=0.7 ultimately determines if your test have passed or not. (You can learn how to unit test chatbots in CI/CD pipelines such as in GitHub actions here.)

Add more tests to stop wasting time on fixing breaking changes to your chatbot 😙
How does your chatbot work under the hood?
The chatbot we just built actually relies on an architecture called Retrieval Augmented Generation (RAG). Retrieval Augmented Generation is a way to make GPT-3.5 smarter by letting it pull in fresh or specific information from an outside source, in this case data.txt. So, when you ask it something, it can give you a more current and relevant answer.
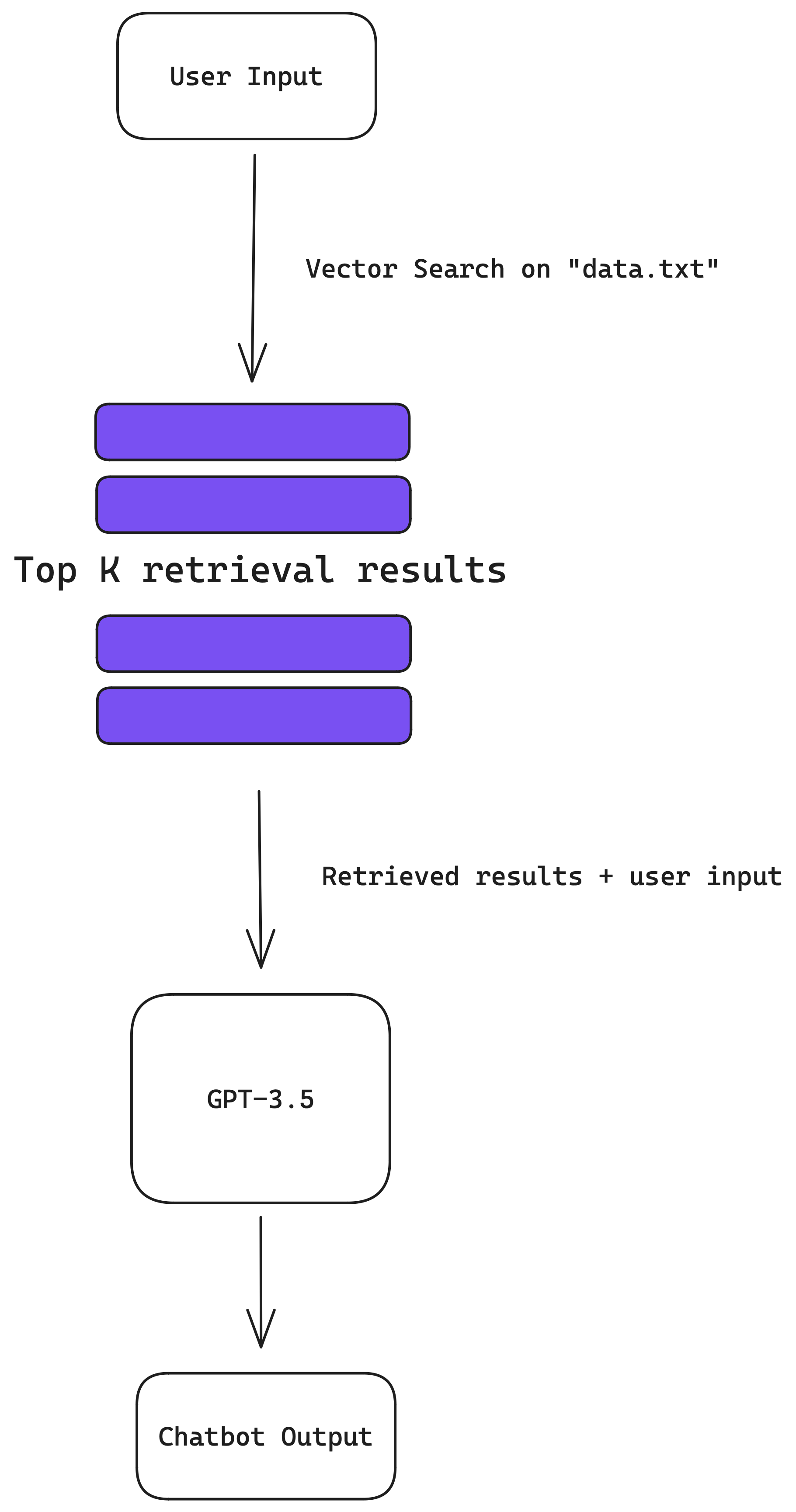
A flowchart shows "User Input" at the top, with an arrow pointing down to "Vector Search on 'data.txt'". Below this, two purple rectangular bars represent "Top K retrieval results". The bottom portion of the image is blacked out.
In the previous two sections, we looked at how tweaking two parameters — text chunk size and number of text chunks used can impact the quality of answer you get from GPT-3.5. This is because when you ask your chatbot a question, lLamaIndex retrieves the most relevant text chunks from data.txt, which GPT-3.5 will use to generate a data augmented answer.
Conclusion
In this article, you've learnt:
- What OpenAI GPT-3.5 is,
- How to build a simple chatbot on your own data using lLamaIndex,
- how to improve the quality of your chatbot,
- how to evaluate your chatbot using Deepeval
- what is RAG and how it works,
This tutorial walks you through an example of a chatbot you can build using lLamaIndex and GPT-3.5. With lLamaIndex, you can create powerful personalized chatbots useful in various applications, such as customer support, user onboarding, sales enablement, and more 🥳
The source code for this tutorial is available here: https://github.com/confident-ai/blog-examples/tree/main/customer-support-chatbot
Thank you for reading!
Do you want to brainstorm how to evaluate your LLM (application)? Ask us anything in our discord. I might give you an "aha!" moment, who knows?
Standardize AI Quality for the entire org, not just individual teams
Give all AI use cases the same quality bar with all-in-one evals, observability, and red teaming, and enforce them at scale.