

Pinecone, the leading closed-source vector database provider, is known for being fast, scalable, and easy to use. Its ability to allow users to perform blazing-fast vector search makes it a popular choice for large-scale RAG applications. Our initial infrastructure for Confident AI, the world’s first open-source evaluation infrastructure for LLMs, utilized Pinecone to cluster LLM observability log data in production. However, after weeks of experimentation, we made the decision to replace it entirely with pgvector. Pinecone’s simplistic design is deceptive due to several hidden complexities, particularly in integrating with existing data storage solutions. For example, it forces a complicated architecture and its restrictive metadata storage capacity made it troublesome for managing data-intensive workloads.
In this article, I will explain why vector databases like Pinecone might not be the best choice for LLM applications and when you should avoid it.
Pinecone Optimizes for Fast Vector Search
On Pinecone’s website, they highlight their key features as:
“Unlock powerful vector search with Pinecone — intuitive to use, designed for speed, and effortlessly scalable.”
But do you really need a dedicated vector database to “unlock powerful vector search”? Given the necessity to cluster and search for log data stored in a PostgreSQL DB, we initially considered Pinecone’s offering due to its promise of fast semantic search and scalability. However, it became evident that the bottleneck in using a closed-source search solution like Pinecone is primarily the latency from network requests, not the search operation itself. Moreover, while Pinecone does provide scalability through the adjustment of resources such as vCPU, RAM, and disk (termed as “pods”), the requirement to deploy another database, solely dedicated to the task of semantic search, unduly complicates a standard data storage architecture. Lastly, due to its strict metadata limitations, a two-step process is required: an initial vector search in Pinecone, followed by a query to the main database to retrieve the data associated with the retrieved vector embeddings.
For those who may not be aware, vector databases were originally developed for large enterprises to store substantial amounts of vector embeddings for training ML models. However, it now appears that every vector database company is advocating for the need for a dedicated vector database provider in your LLM application tech stack.
Pinecone, Not So Scalable After All
While Pinecone’s s2, p1, and p2 pods can scale both horizontally to increase QPS (query per second) or vertically (x1, x2, x4, x8) to fit more vectors on a single pod, it still lacks the integrations to address significant challenges faced by large-scale workloads:
- Data Synchronization Issues — Pinecone solely utilizes APIs for sending and receiving data from its indexes. This approach, while straightforward, lacks mechanisms to ensure data synchronization with the primary datasource. In data-intensive applications, it’s a prevalent issue to find indexes becoming desynchronized from the source, especially following periods of high data-intensity workload.
- Restrictive Data Storage — Pinecone limits metadata to 40KB per vector, necessitating additional queries to the main datasource for extra metadata retrieval. This limit also requires additional error handling to manage data storage overflows.
These deficiencies turn Pinecone into a scalability hell due to its architectural limitations in data handling. For these reasons, you should consider adopting a vectorized option of your current data storage solution where possible, instead of using a standalone vector database.
Standardize AI Quality for the entire org, not just individual teams
Give all AI use cases the same quality bar with all-in-one evals, observability, and red teaming, and enforce them at scale.
Other Shortcomings of Pinecone’s Features
- Closed source — this typically isn’t a problem for most software applications, but for applications that’s optimized for speed this means network latencies will become the bottleneck no matter how fast your vector search is.
- Incomplete database solution — lacks row-level security, database backups, bulk operations, and complete ACID compliance,
- Lacks support for different indexing algorithms — instead uses a proprietary ANN (approximate nearest neighbor) index and the only way to adjust query accuracy and speed is to change the pod type.
Previously pgvector only supported IVFFlat indexing which was known for merely average performance, but ever since HNWS was introduced it now outperforms all three of pod types when utilizing the ANN benchmarking methodology, a standard for benchmarking vector databases. (although interestingly, there are benchmarks that shows pgvector’s IVFFlat index outperforms s1 pods on the same compute and manages 143% more QPS)
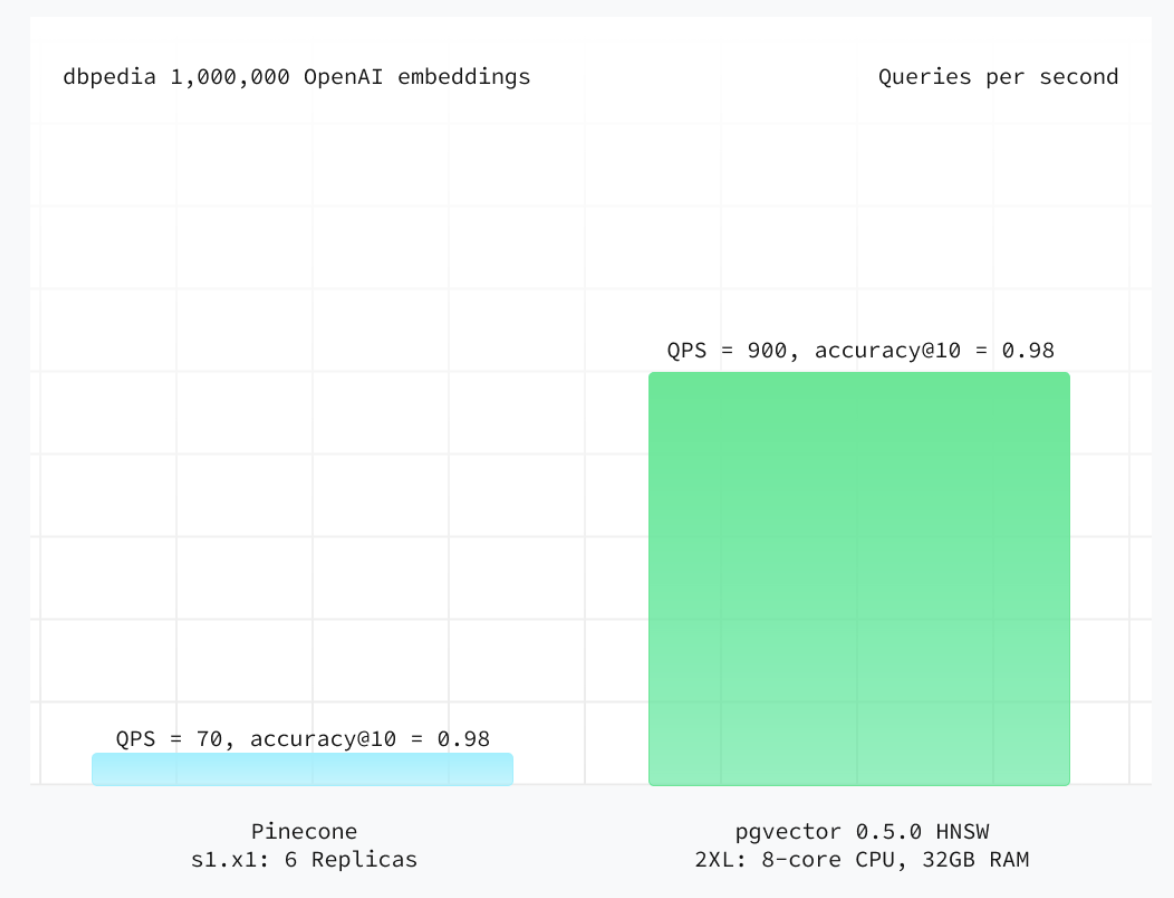
Data taken from Supabase. It shows that for all three pod types (scaled vertically to match storage capacity), pgvector outperforms Pinecone in both accuracy and QPS on the same compute.
PGVector is Not Perfect Either
- A common issue with using a vectorized offering of your preferred data storage engine is the difficulty in unifying fragmented data sources, which is necessary for conducting vector searches on your data.
- Pinecone offers a potential cost advantage. For about $160 monthly, you can use a p1.x2 pod without needing replicas and still achieve close to 60 QPS with a high accuracy of 0.99. For roughly the same price for managed postgres services, you might run into issues with the entire index not fitting into RAM. This situation would lead to relying on a slower KNN search method that doesn’t use indexes. However, you could also scale vertically to hold more vectors similar to upsizing your pods.
Conclusion
Pinecone has excellent features for POC projects but requires substantial effort to maintain a scalable and performant search infrastructure. It allows you to perform vector search on multiple data sources, but however was unnecessary for our use case at Confident. If you’re looking to perform vector search on existing, single-sourced data, consider adopting a data storage solution with a built-in vectorized option instead of using a standalone vector database.
Find us on GitHub ⭐ to follow our journey in building the world’s first open-source evaluation infrastructure for LLMs, and thank you for reading.
Do you want to brainstorm how to evaluate your LLM (application)? Ask us anything in our discord. I might give you an "aha!" moment, who knows?
Standardize AI Quality for the entire org, not just individual teams
Give all AI use cases the same quality bar with all-in-one evals, observability, and red teaming, and enforce them at scale.